library(tidyverse)
library(tidymodels)
library(ggfortify) #autoplot para diagnósticos
library(rstanarm) #para bayesiana
library(poissonreg) #modelo Poisson
#Siempre que uses tidymodels
tidymodels_prefer()Regresiones (parte 1)
Paquetes y datos a utilizar
A lo largo de esta sección usaremos los siguientes paquetes:
En general usaremos la filosofía tidymodels para combinar los resultados con el tidyverse. Si quieres saber más de tidymodels te recomiendo checar su libro o su página web.
Embarazo adolescente y pobreza
Para los datos usaremos la información de Utts y Heckard para determinar si hay una relación entre embarazo adolescente y pobreza.
emb_pob <- read_delim("https://online.stat.psu.edu/stat462/sites/onlinecourses.science.psu.edu.stat462/files/data/poverty/index.txt")Rows: 51 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): Location
dbl (5): PovPct, Brth15to17, Brth18to19, ViolCrime, TeenBrth
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Las variables Brth15to17 y Brth18to19 son las tasas brutas de natalidad por cada 1000 mujeres (en el año 2002) en adolescentes de 15 a 17 años y de 18 a 19 respectivamente. La variable PovPct representa la proporción (%) de la población que vive bajo la línea de pobreza en cada una de las entidades de EEUU (Location). Las variables ViolCrime y TeenBrth no se explican por lo que no las usaremos.
Regresiones lineales
Usaremos Brth15to17 y PovPct para estudiar si hay una relación entre la tasa de natalidad en adolescentes y el porcentaje de la población en pobreza. Para ello comenzaremos con graficar:
ggplot(emb_pob) +
geom_point(aes(x = PovPct, y = Brth15to17), color = "#bc5090", size = 3) +
labs(
x = "Porcentaje en pobreza",
y = "Tasa bruta de natalidad (por cada 1,000 mujeres adolescentes)",
title = "Relación entre tasa bruta de natalidad en adolescentes\nde 15 a 19 años y porcentaje en pobreza"
) +
theme_bw()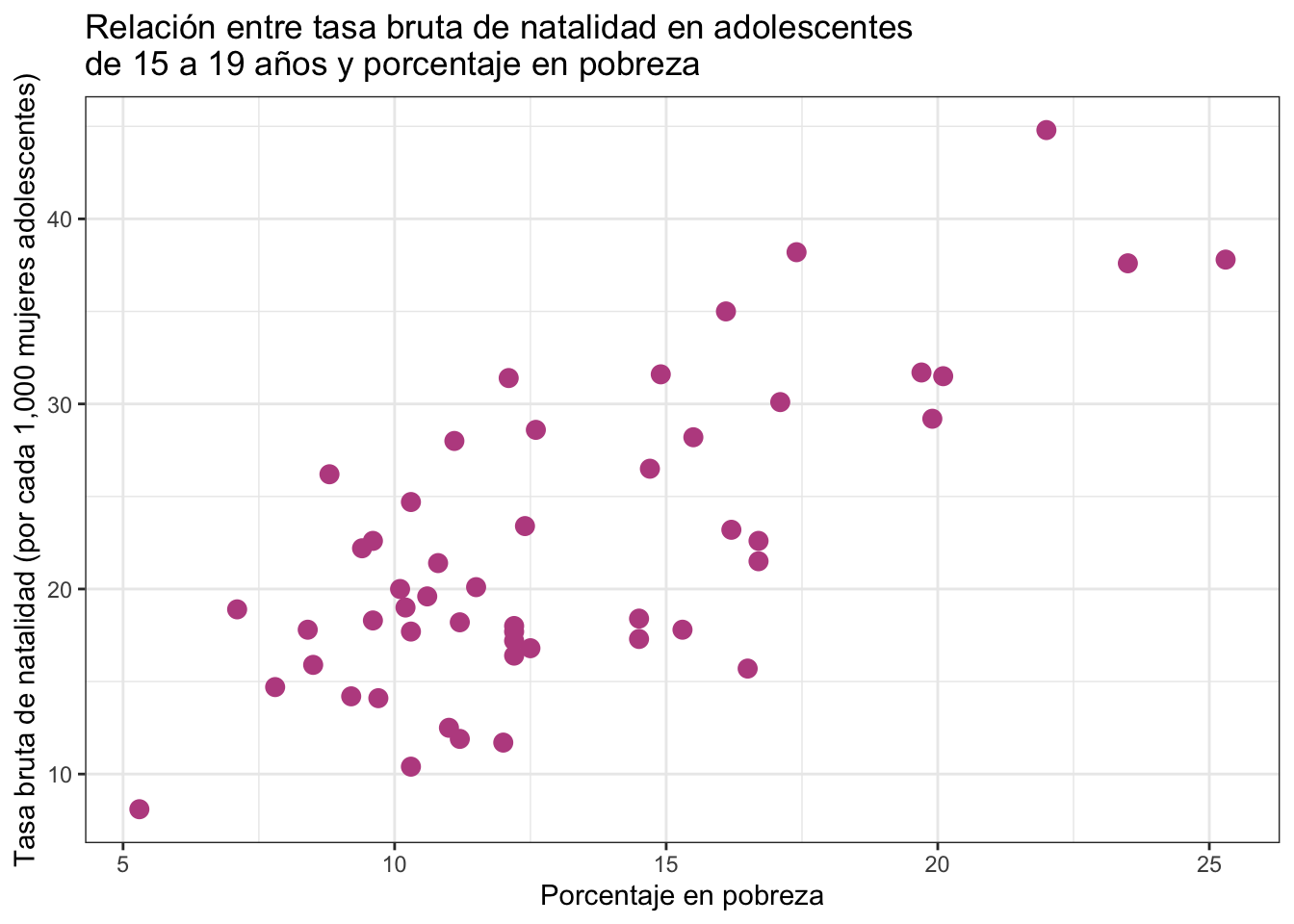
Parece que a mayor porcentaje de pobreza, mayor tasa bruta de natalidad en adolescentes.
Planteamiento clásico
Si la relación fuera perfecta todos los casos caerían exactamente en una línea recta como sigue:
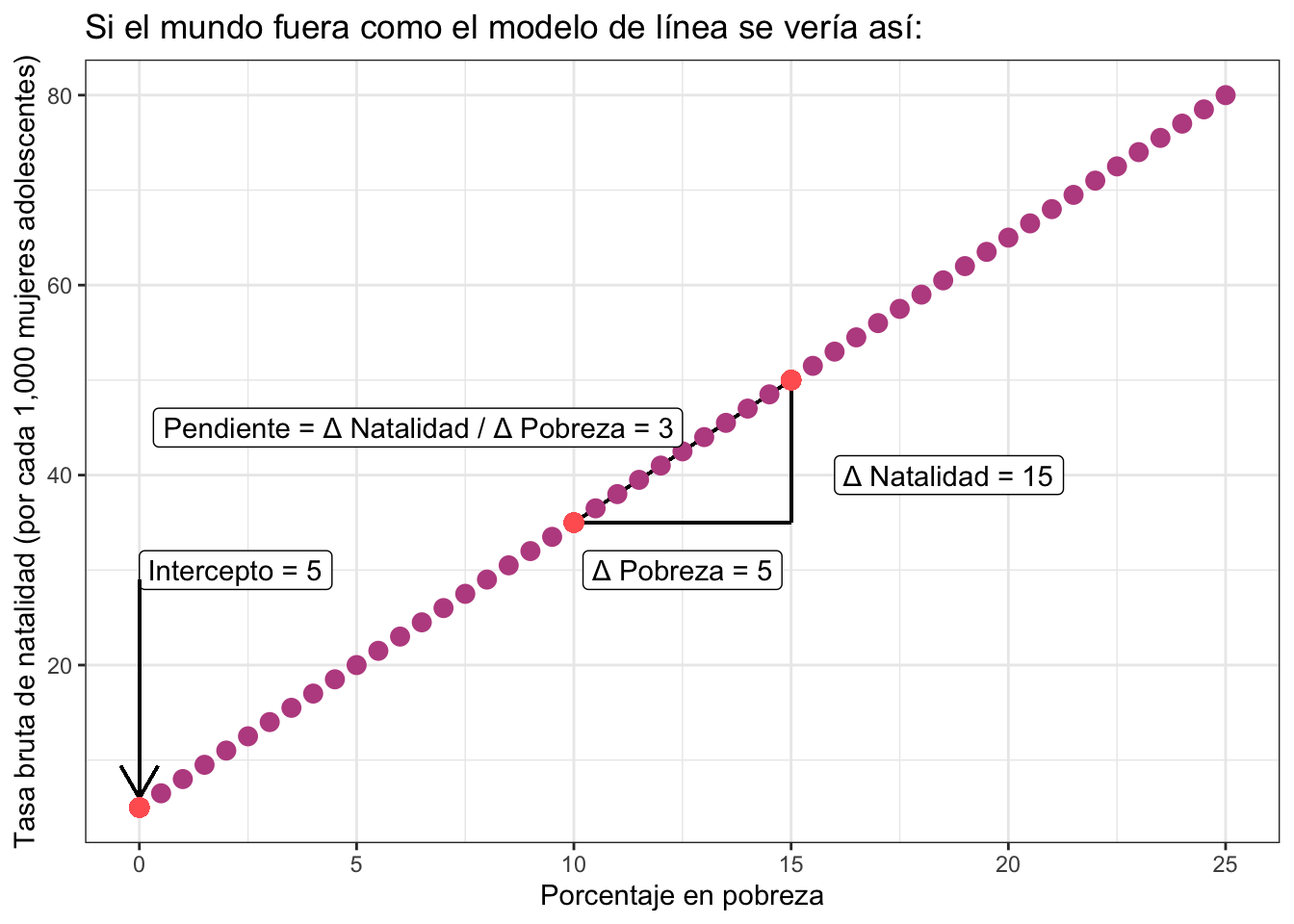
donde es necesario especificar dos parámetros: el intercepto (el valor que toma cuando la \(x\) en este caso PovPct vale cero) y la pendiente (el valor que relaciona por cada unidad de aumento en PovPct cuánto aumenta Brth15to17).
La ecuación de la línea está dada por:
\[ y = \beta_0 + \beta_1 x \]
donde \(\beta_0\) es el intercepto y \(\beta_1\) la pendiente. Usando la terminología de arriba:
\[ \text{Brth15to17} = \text{Intercepto} + \text{Pendiente}\times \text{PovPct} \] en particular en ese ejemplo:
\[ \text{Brth15to17} = 5 + 3\cdot \text{PovPct} \]
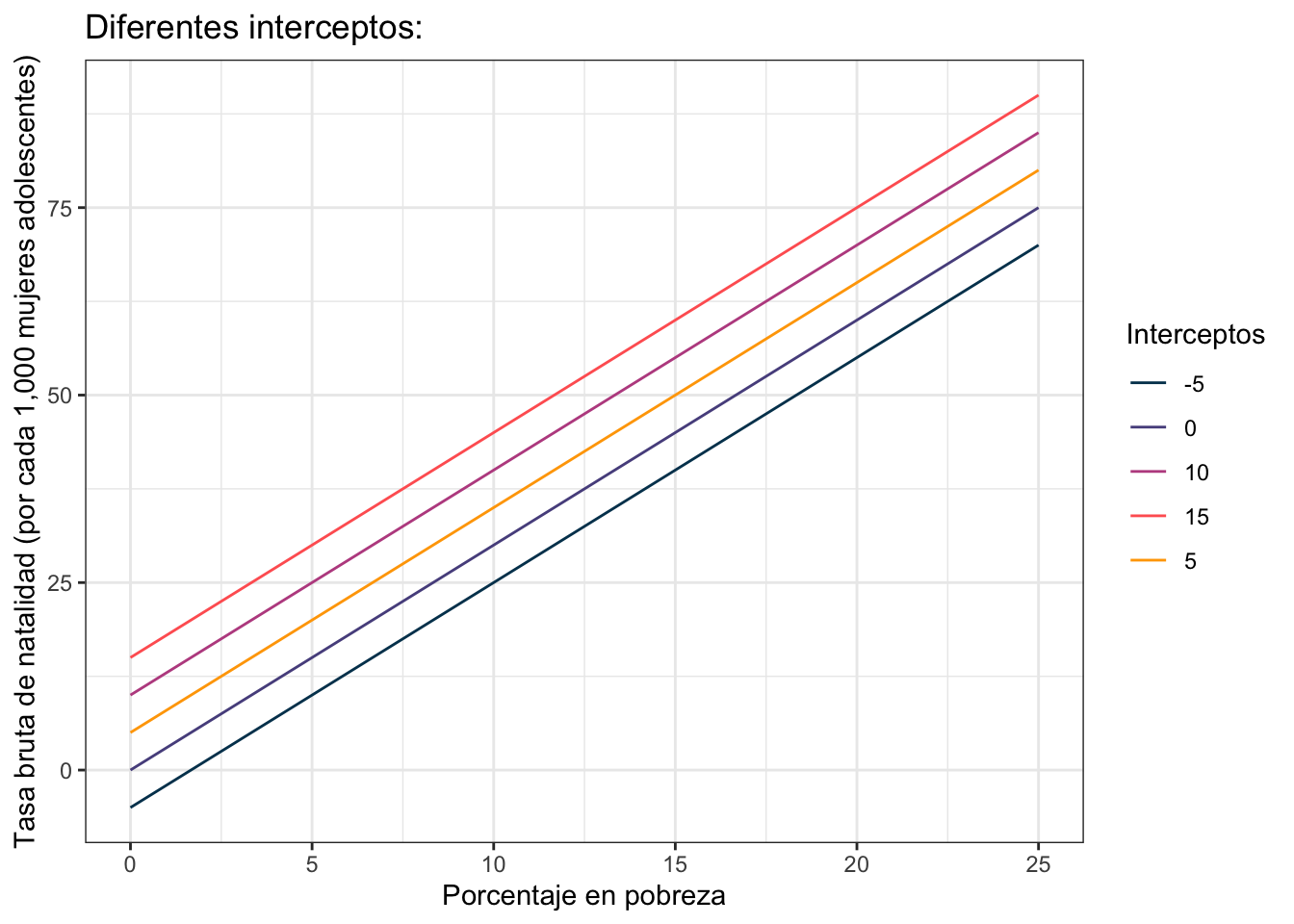
La idea es que el intercepto (\(\beta_0\) ó \(5\)) te indica dónde comienza tu línea cuando no tienes \(x\)’s (es decir cuando \(\text{PovPct} = 0\)). El intercepto controla la altura de la línea como puedes ver en la siguiente gráfica donde puse varios interceptos distintos:
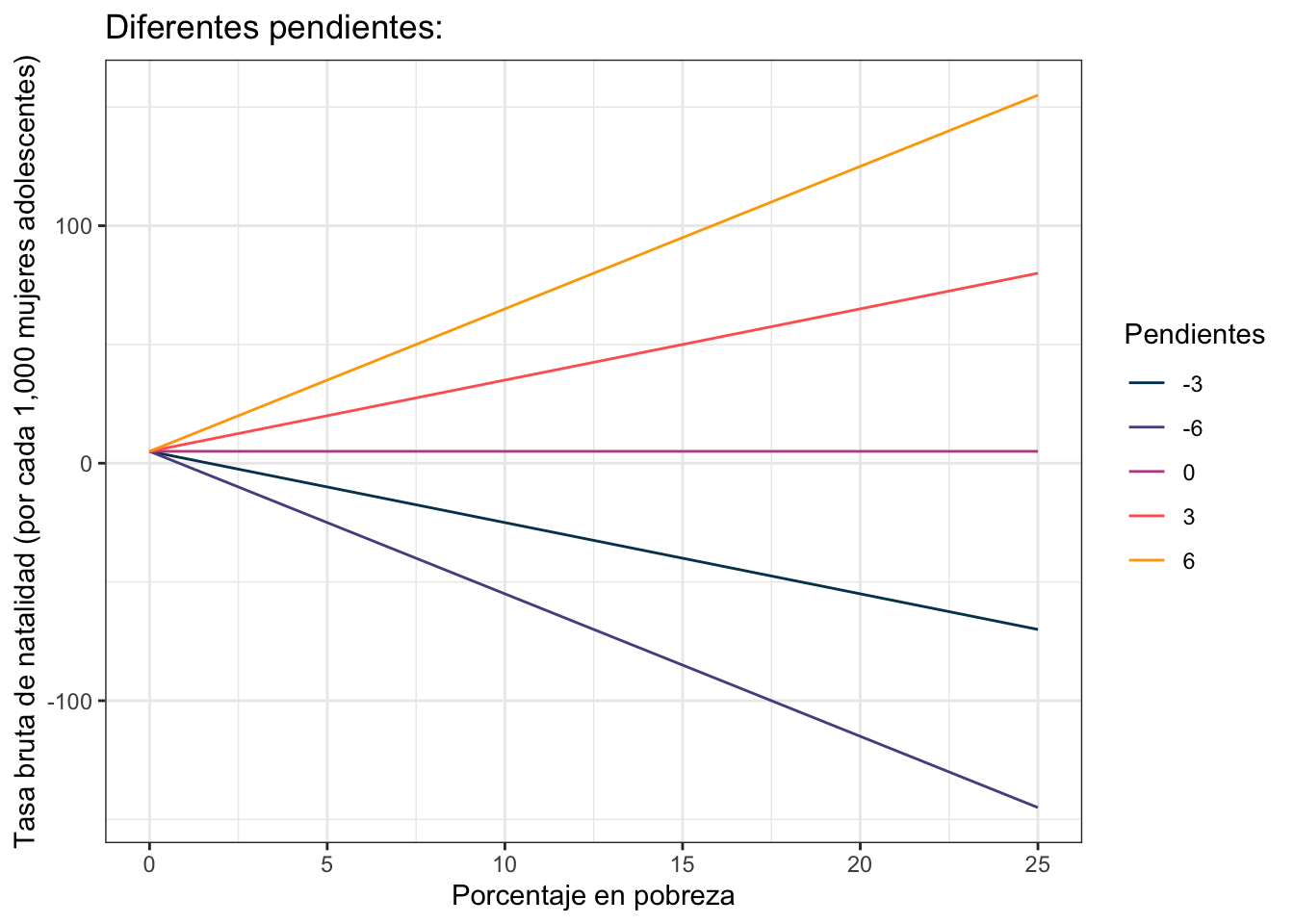
por otro lado la idea de la pendiente (\(\beta_1\) ó \(3\)) es retratar cómo cambia la \(y\) (en este caso \(\text{Brth15to17}\)) por cada unidad que cambia la \(x\) (en este caso \(\text{PovPct}\)). El valor de \(3\) por ejemplo indica que por cada aumento en 1 en \(\text{PovPct}\) la variable \(\text{Brth15to17}\) aumenta en \(3\). Este cambio es proporcional; es decir si ahora \(\text{PovPct}\) aumenta 4 (por decir algo) \(\text{Brth15to17}\) aumenta \(3\times 4 = 12\) unidades. La siguiente gráfica muestra varias líneas todas comenzando en el mismo intercepto de \(5\):
Como ya vimos en la primer figura el mundo no es tan perfecto que todo sea una línea recta. Hay un poco de aleatoriedad involucrada (sea por variables no medidas, por errores de medición o porque el mundo no sea determinista). Por lo cual se plantea que en lugar de que la \(y\) sea exactamente \(\beta_0 + \beta_1 x\) planteamos que la \(y\) proviene de una variable aleatoria normal donde la media de esa normal es \(\beta_0 + \beta_1 x\); es decir:
\[ y \sim \textrm{Normal}( \beta_0 + \beta_1 x, \sigma^2) \]
o dicho de otra manera:
\[ \text{Brth15to17} \sim \textrm{Normal}(\text{Intercepto} + \text{Pendiente}\times \text{PovPct}, \sigma^2) \]
donde la \(\sigma^2\) es la varianza de dicha normal. Puesto gráficamente lo que esto quiere decir es que si, por ejemplo, el intercepto es \(5\) y la pendiente \(3\) entonces cada medición de \(y\) viene de una normal ligeramente distinta:
\[ \text{Brth15to17} \sim \textrm{Normal}(5 + 3\times \text{PovPct}, \sigma^2) \]
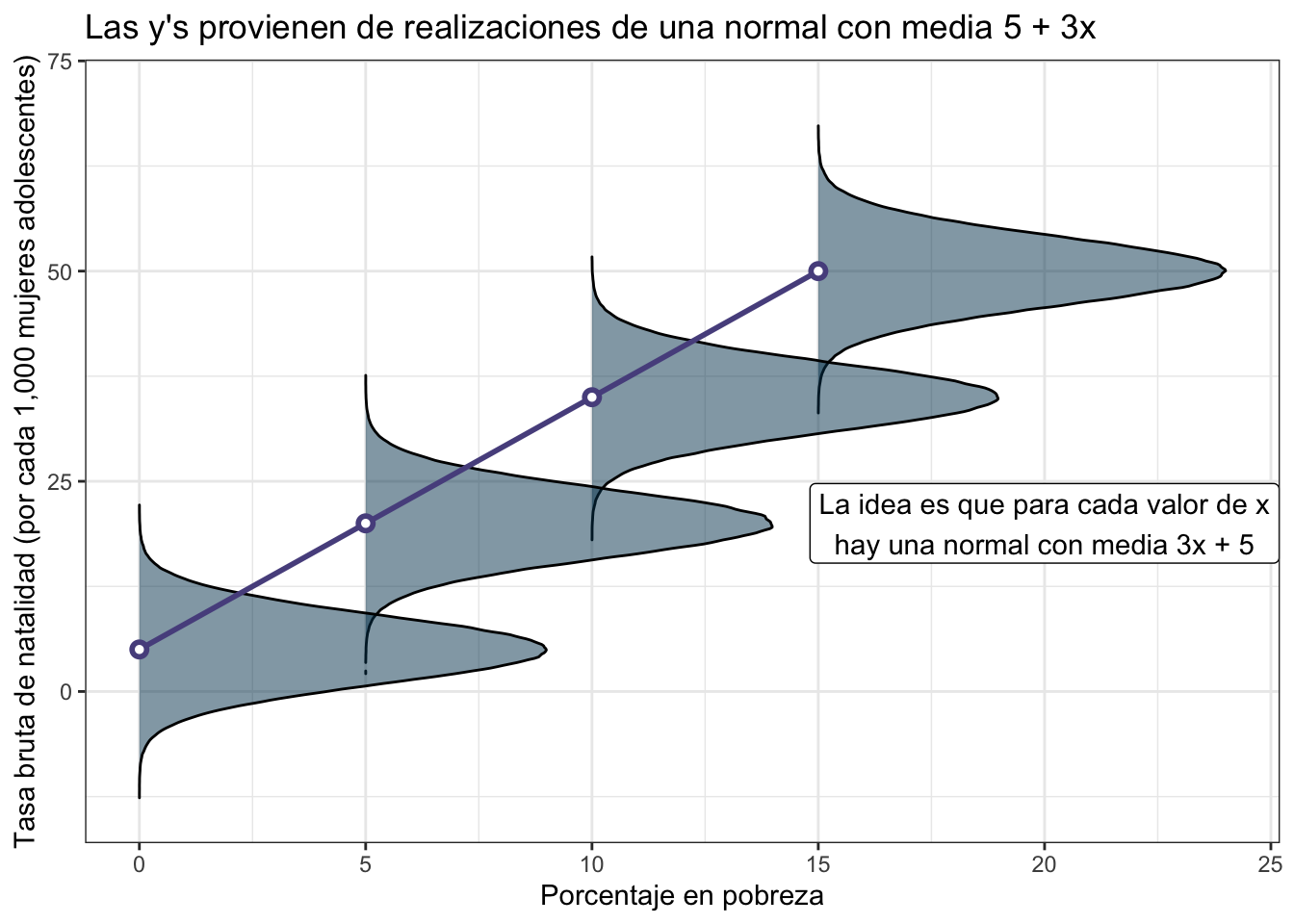
Dicho de otra forma, suponemos que en un mundo perfecto los valores de \(y\) (Brth15to17) estarían completamente determinados por los de \(x\) (PovPct) mediante la ecuación de la recta. Pero como el mundo no es perfecto entonces la \(y\) proviene de una normal con promedio dado por la recta. Los puntos (como puedes ver an la siguiente gráfica) se centran más en torno a los promedios de las normales sin embargo están colocados aleatoriamente pues corresponden a distintas realizaciones de \(y\).
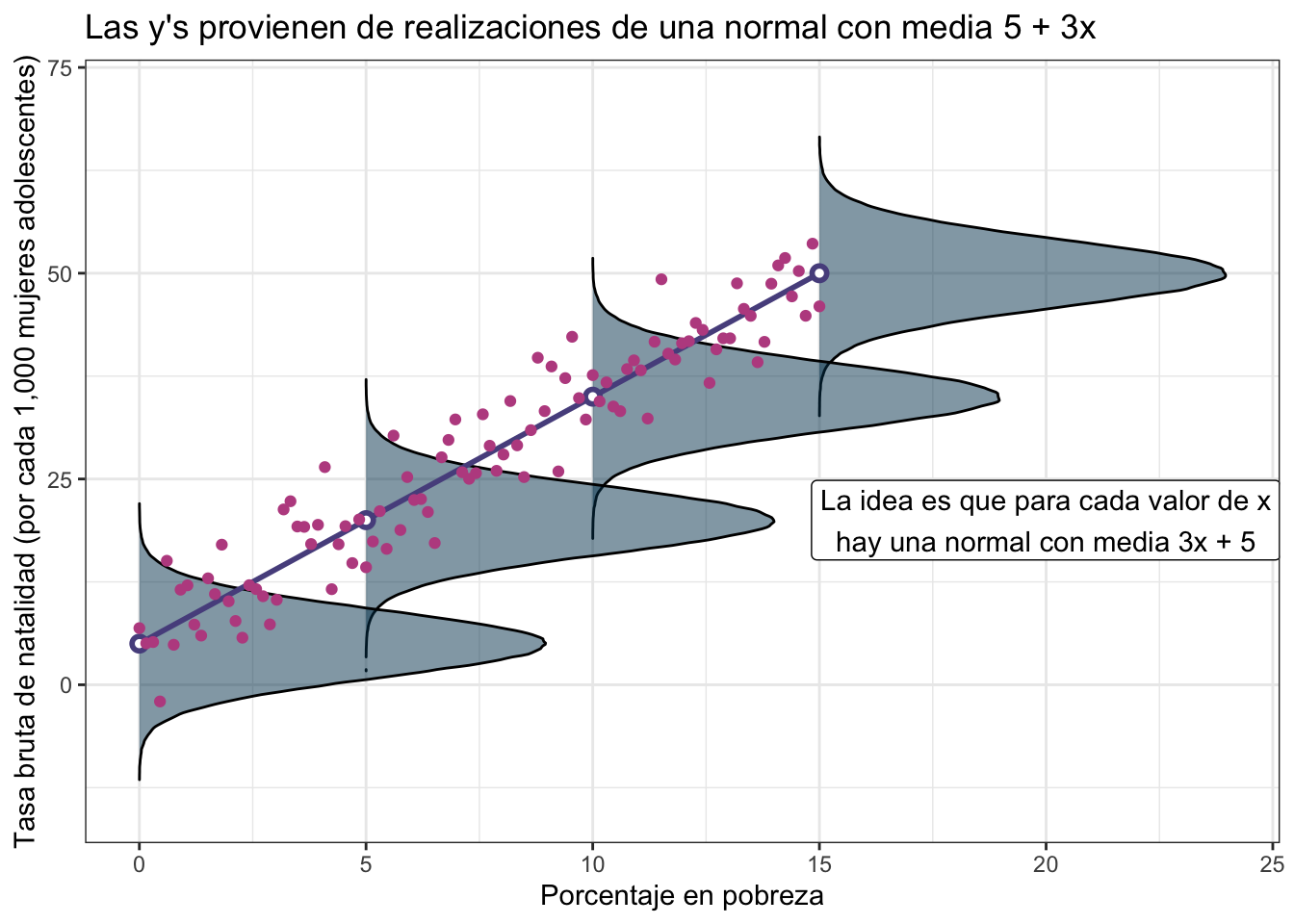
Por ejemplo si el porcentaje de pobreza (PovPct) es \(10\) entonces la normal de la que provienen estos datos es:
\[ \text{Brth15to17} \sim \textrm{Normal}(\underbrace{5 + 3\times 10}_{35}, \sigma^2) \]
mientras que si el porcentaje en pobreza es \(20\) entonces la normal es:
\[ \text{Brth15to17} \sim \textrm{Normal}(\underbrace{5 + 3\times 20}_{65}, \sigma^2) \]
Por supuesto que no hay nada de especial con el modelo normal y alguien podría elegir otra distribución (por ejemplo una Gamma) y establecer que:
\[ \text{Brth15to17} \sim \textrm{Gamma}(\text{Intercepto} + \text{Pendiente}\times \text{PovPct}, \beta) \]
Estos modelos son algunos de los lineales generalizados y los discutiremos más adelante. Por ahora nos quedaremos con la idea del modelo dado por:
\[ \text{Brth15to17} \sim \textrm{Normal}(\text{Intercepto} + \text{Pendiente}\times \text{PovPct}, \sigma^2) \]
Nota quizá conoces la regresión lineal bajo la idea clásica de que \[ y = \beta_0 + \beta_1 x + \epsilon \] donde \(\epsilon\sim\text{Normal}(0,\sigma^2)\) son los errores normales. Esta definición es equivalente a la que damos aquí pues por propiedades aditivas de la normal \(\epsilon + \beta_0 + \beta_1 x\) se sigue distribuyendo normal pero con la media ahora dada por lo agregado (\(\beta_0 + \beta_1 x\)). Las ventajas de esta notación es que un modelo para regresión Poisson es simplemente: \[ y \sim \textrm{Poisson}(\beta_0 + \beta_1 x) \] y un modelo para regresión logística es: \[ y \sim \textrm{Bernoulli}\big(\textrm{logit}(\beta_0 + \beta_1 x)\big) \]
Planteamiento en R
Lo que nos toca ahora es programar nuestro modelo para ello seguiremos la filosofía de tidymodels que pretende unificar bajo la misma notación todos los modelos. La notación básica es como sigue:
modelo %>%
set_engine("tipo de ajuste") %>%
fit("formula a ajustar", data = tus_datos)A partir del ajuste se pueden predecir cosas con predict:
modelo %>%
set_engine("tipo de ajuste") %>%
fit("formula a ajustar", data = tus_datos) %>%
predict()o extraer nuevos datos con extract_fit_engine y tidy:
modelo %>%
set_engine("tipo de ajuste") %>%
fit("formula a ajustar", data = tus_datos) %>%
extract_fit_engine() %>%
tidy()Comencemos con nuestro primer modelo: una regresión lineal clásica dada por:
\[ \text{Brth15to17} \sim \textrm{Normal}(\text{Intercepto} + \text{Pendiente}\times \text{PovPct}, \sigma^2) \]
En R el engine que necesitamos es “lm” que es el clásico:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
modelo_ajustado <- linear_reg() %>%
set_engine("lm") %>%
fit(Brth15to17 ~ PovPct, data = emb_pob) #Notación y ~ xNota que a diferencia de Stata, R no arroja demasiados resultados. Podemos usar extract_fit_engine combinado con summary para obtenerlos:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
modelo_ajustado %>%
extract_fit_engine() %>%
summary()
Call:
stats::lm(formula = Brth15to17 ~ PovPct, data = data)
Residuals:
Min 1Q Median 3Q Max
-11.2275 -3.6554 -0.0407 2.4972 10.5152
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.2673 2.5297 1.687 0.098 .
PovPct 1.3733 0.1835 7.483 1.19e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.551 on 49 degrees of freedom
Multiple R-squared: 0.5333, Adjusted R-squared: 0.5238
F-statistic: 56 on 1 and 49 DF, p-value: 1.188e-09o bien con tidy si deseamos nos devuelva una tabla de resultados:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
modelo_ajustado %>%
extract_fit_engine() %>%
tidy()# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 4.27 2.53 1.69 0.0980
2 PovPct 1.37 0.184 7.48 0.00000000119Según el tipo de regresión que estemos haciendo es el tipo de tabla que regresa tidy (ver ?tidy). En particular, por ejemplo, podemos modificar para que devuelva intervalos de confianza al 90%:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
modelo_ajustado %>%
tidy(conf.int = T, conf.level = 0.90)# A tibble: 2 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 4.27 2.53 1.69 0.0980 0.0260 8.51
2 PovPct 1.37 0.184 7.48 0.00000000119 1.07 1.68En este caso, el modelo estima que el intercepto (\(\beta_0\)) es \(4.27\) y la pendiente (\(\beta_1\)) es \(1.37\). Como son estimadores del verdadero valor se denotan con gorrito: \(\hat\beta_0 = 4.27\) y \(\hat\beta_1 = 1.37\).
Podemos utilizar la función de predict para que el modelo nos muestre cómo cree que son los verdaderos valores en relación a los ajustados:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
predichos <- modelo_ajustado %>%
predict(new_data = emb_pob)
intervalo_predichos <- modelo_ajustado %>%
predict(new_data = emb_pob, type = "pred_int", level = 0.95)
#Juntamos los predichos con los observados
obs_y_modelo <- emb_pob %>%
cbind(predichos) %>%
cbind(intervalo_predichos)
#Graficamos
ggplot(obs_y_modelo) +
geom_ribbon(aes(x = PovPct, ymin = .pred_lower, ymax = .pred_upper),
fill = "#003f5c", size = 1, alpha = 0.5) +
geom_point(aes(x = PovPct, y = Brth15to17), color = "#bc5090", size = 3) +
geom_line(aes(x = PovPct, y = .pred),
color = "#003f5c", size = 1) +
labs(
x = "Porcentaje en pobreza",
y = "Tasa bruta de natalidad (por cada 1,000 mujeres adolescentes)",
title = "Relación entre tasa bruta de natalidad en adolescentes\nde 15 a 19 años y porcentaje en pobreza"
) +
theme_bw()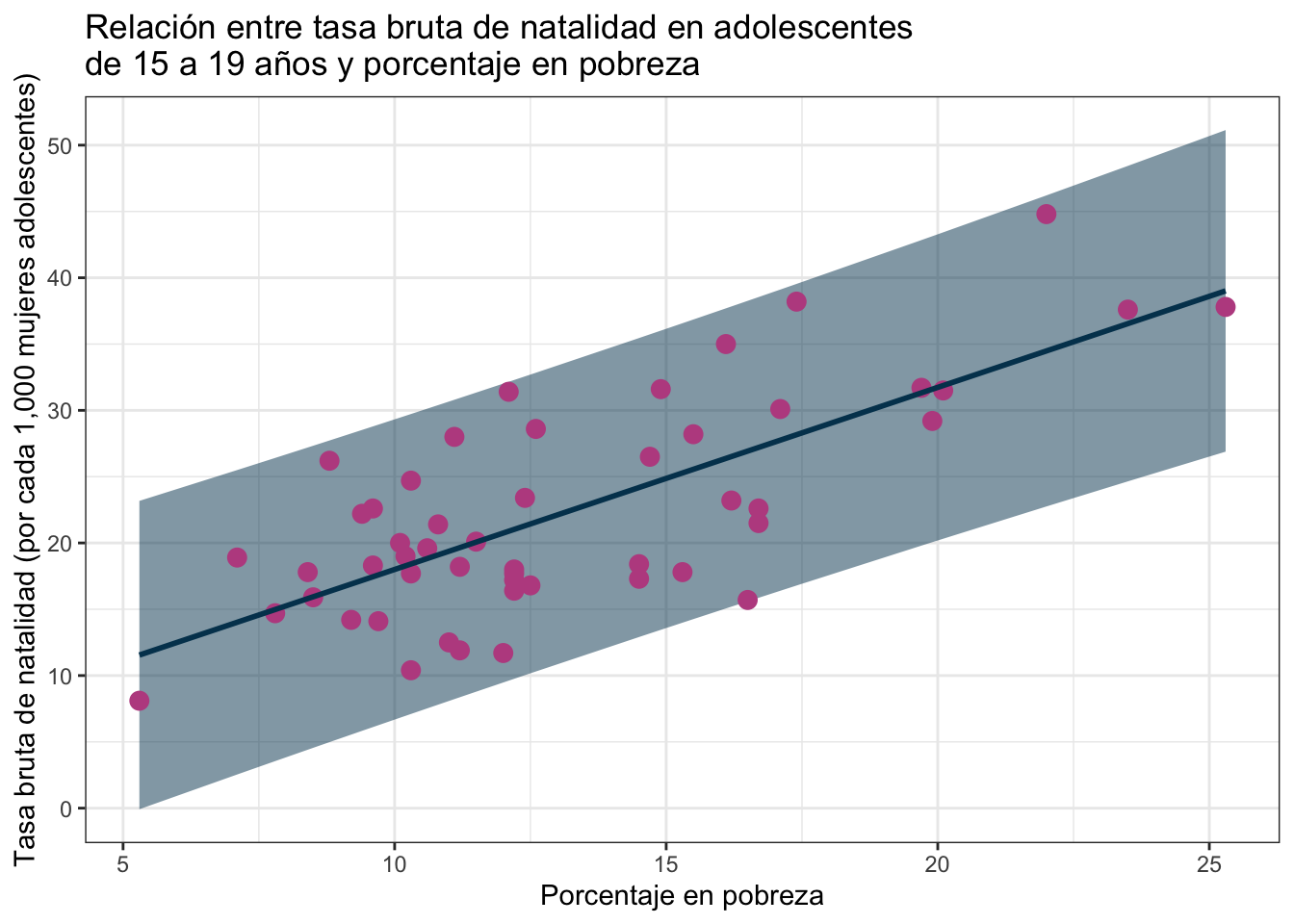
Nada más a ojo no parece que el modelo sea el mejor pues puedes ver que no explica bien la variabilidad (los observados varían mucho respecto al intervalo). La \(R^2\), una métrica que explica cuánto de la varianza captura el modelo tampoco es muy buena:
resumen_ajuste <- modelo_ajustado %>%
extract_fit_engine() %>%
summary()
#R^2 clásica
resumen_ajuste$r.squared[1] 0.533328#R^2 ajustada
resumen_ajuste$adj.r.squared[1] 0.523804Podemos checar las diferentes gráficas de diagnóstico:
library(ggfortify)
autoplot(modelo_ajustado, which = 1:5)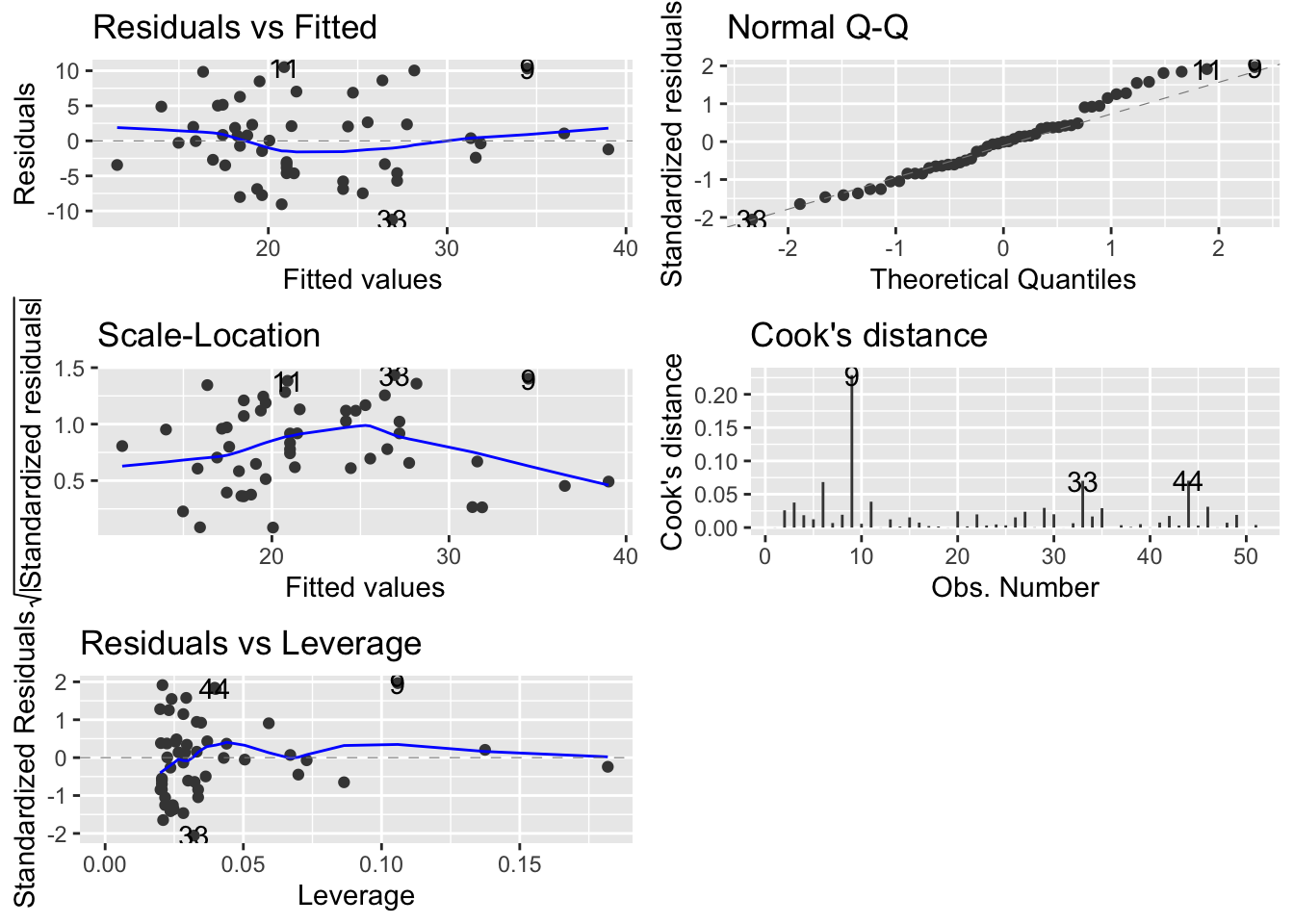
Veamos qué significa cada una de ellas y juguemos un poco con R para irlas modificando.
Residuales contra ajustados
Los residuales son la diferencia entre el modelo (\(\hat{y}\)) y lo real \(y\). En el caso que estábamos trabajando tenemos que con nuestro modelo podemos predecir los valores de Brth15to17 a partir del porcentaje en pobreza PovPct. A los valores predichos por el modelo de Brth15to17 les ponemos un gorro encima y los llamamos: \(\widehat{\text{Brth15to17}}\). Estos están dados por la siguiente función:
\[ \widehat{\text{Brth15to17}} = 4.26 + 1.37 \cdot \text{PovPct} \]
por ejemplo para el porcentaje en pobreza de \(20.1\) obtendríamos:
\[ \widehat{\text{Brth15to17}} = 4.26 + 1.37 \cdot \text{PovPct} = 31.797 \]
por otro lado el verdadero valor de cuando el PovPct es \(20.1\) (estado de Alabama) es \(\text{Brth15to17} = 31.5\). La diferencia entre el verdadero valor (\(\text{Brth15to17} = 31.5\)) y el predicho por el modelo (\(\widehat{\text{Brth15to17}} = 31.797\)) se conoce como el residual. La idea es que en un modelo bueno no debe haber patrones en los residuales (todos deben de flotar en torno al cero pero no mostrar un patrón).
Veamoslo en nuestra base:
obs_y_modelo <- obs_y_modelo %>%
mutate(residuales = Brth15to17 - .pred)
ggplot(obs_y_modelo) +
geom_point(aes(x = .pred, y = residuales), color = "#ff6361") +
labs(
x = "Valores ajustados (predichos)",
y = "Residuales",
title = "Residuales vs ajustados"
) +
theme_bw() +
geom_hline(aes(yintercept = 0), linetype = "dashed")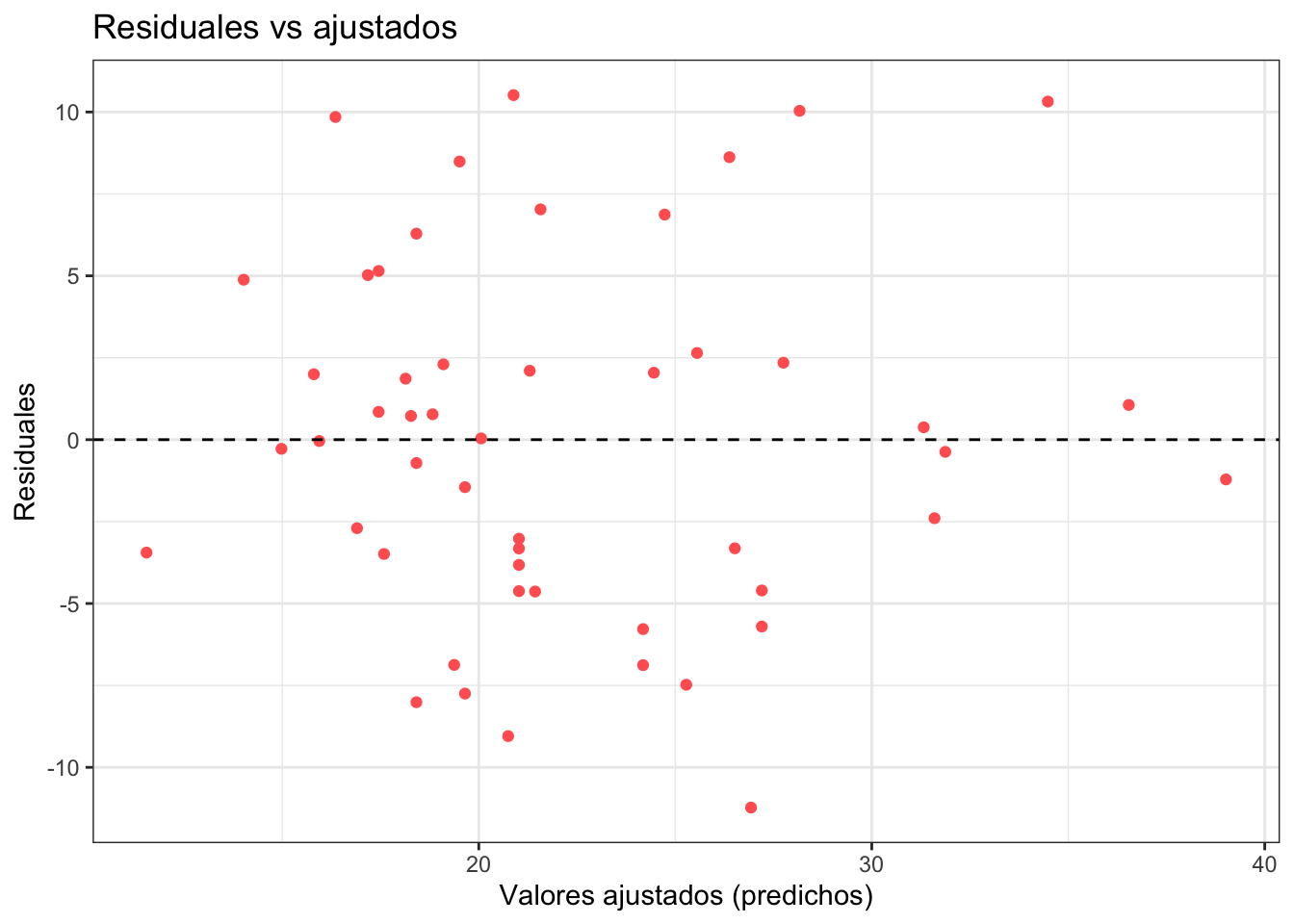
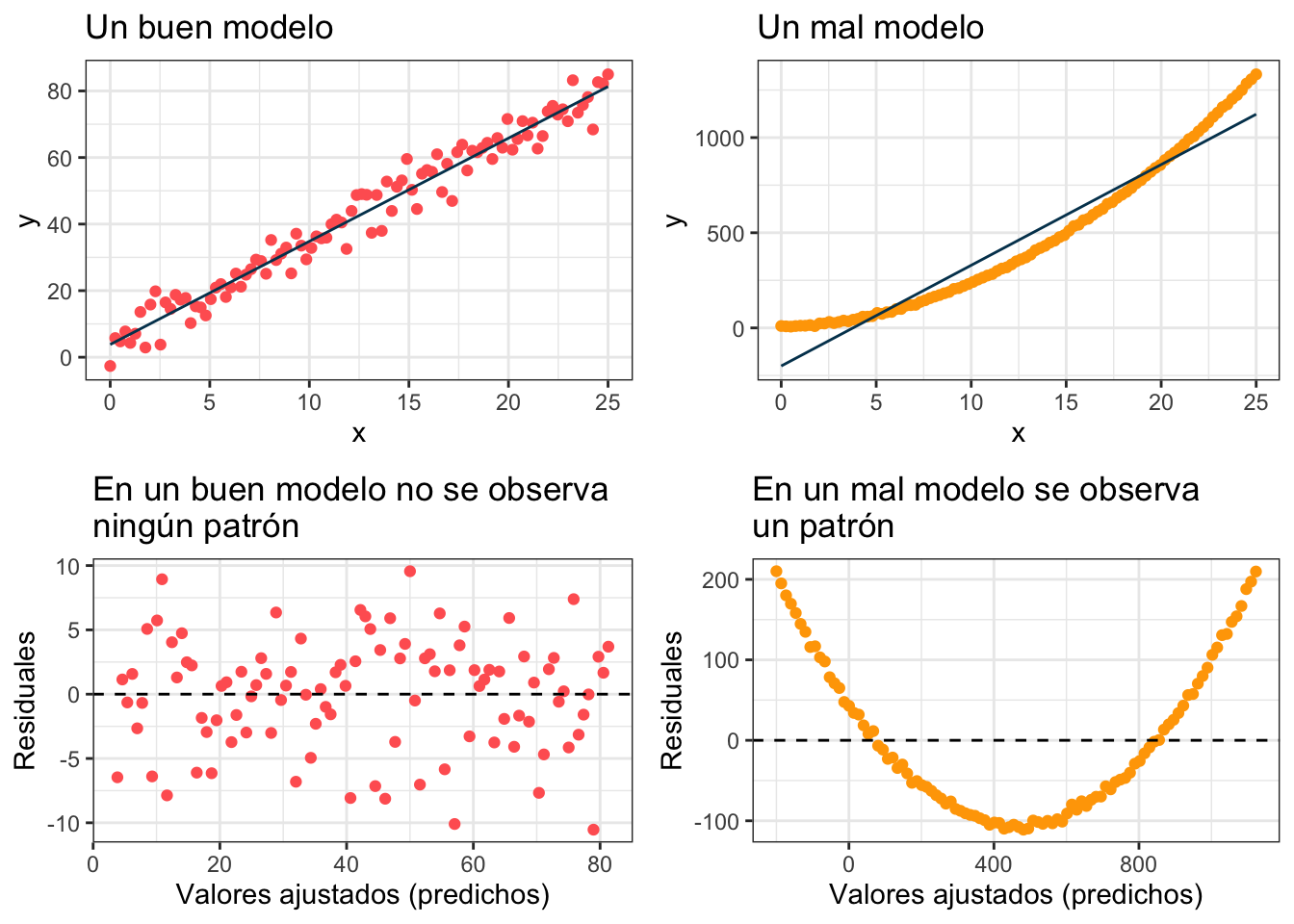
En esta gráfica el modelo predice mejor rumbo al final que en medio y esto parece estar corroborado por la gráfica del modelo (previa). Nada más para darnos una idea veamos una gráfica de malos residuales y una de buenos
Escala locación
Representa la escala locación contra los residuales estandarizados. La idea de la gráfica es ver que la varianza \(\sigma^2\) del modelo no cambie conforme cambia la \(x\) (propiedad de homoscedasticidad). Para ello graficamos los residuales estandarizados dados por los residuales mismos dividos entre su desviación estándar:
\[ r_{\text{Std}} = \frac{\hat{y} - y}{\text{sd}(\hat{y} - y)} = \frac{\text{Residuales}}{\text{sd}\big(\text{Residuales}\big)} \]
estos residuales estandarizados los podemos calcular en R como sigue:
obs_y_modelo <- obs_y_modelo %>%
mutate(residuales_std = residuales/sd(residuales))Si los graficamos contra los valores ajustados no deberíamos de ver ningún patrón:
ggplot(obs_y_modelo) +
geom_point(aes(x = .pred, y = residuales_std), color = "#ff6361") +
labs(
x = "Valores ajustados (predichos)",
y = "Residuales estandarizados",
title = "Escala Locación"
) +
theme_bw() +
geom_hline(aes(yintercept = 0), linetype = "dashed")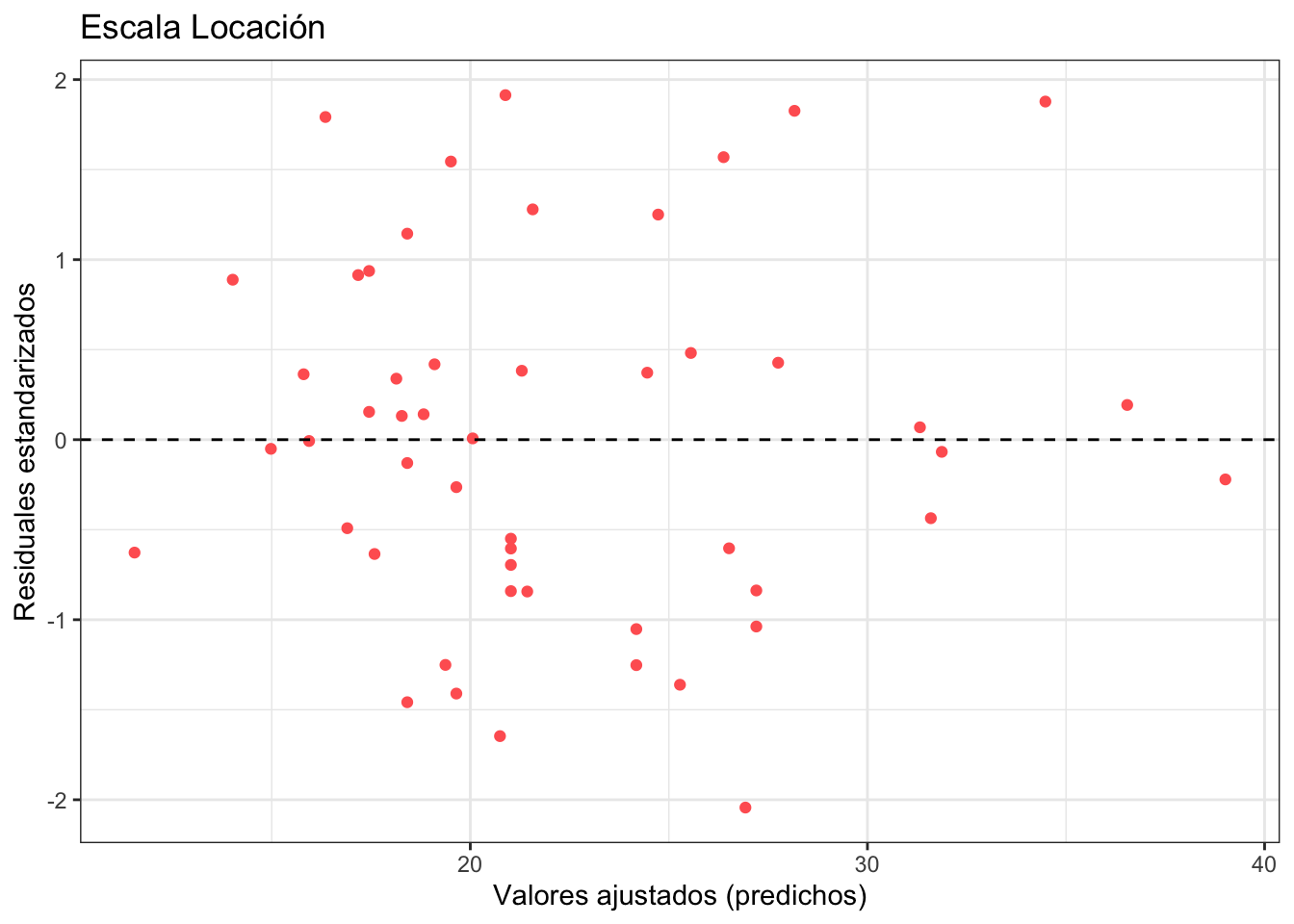
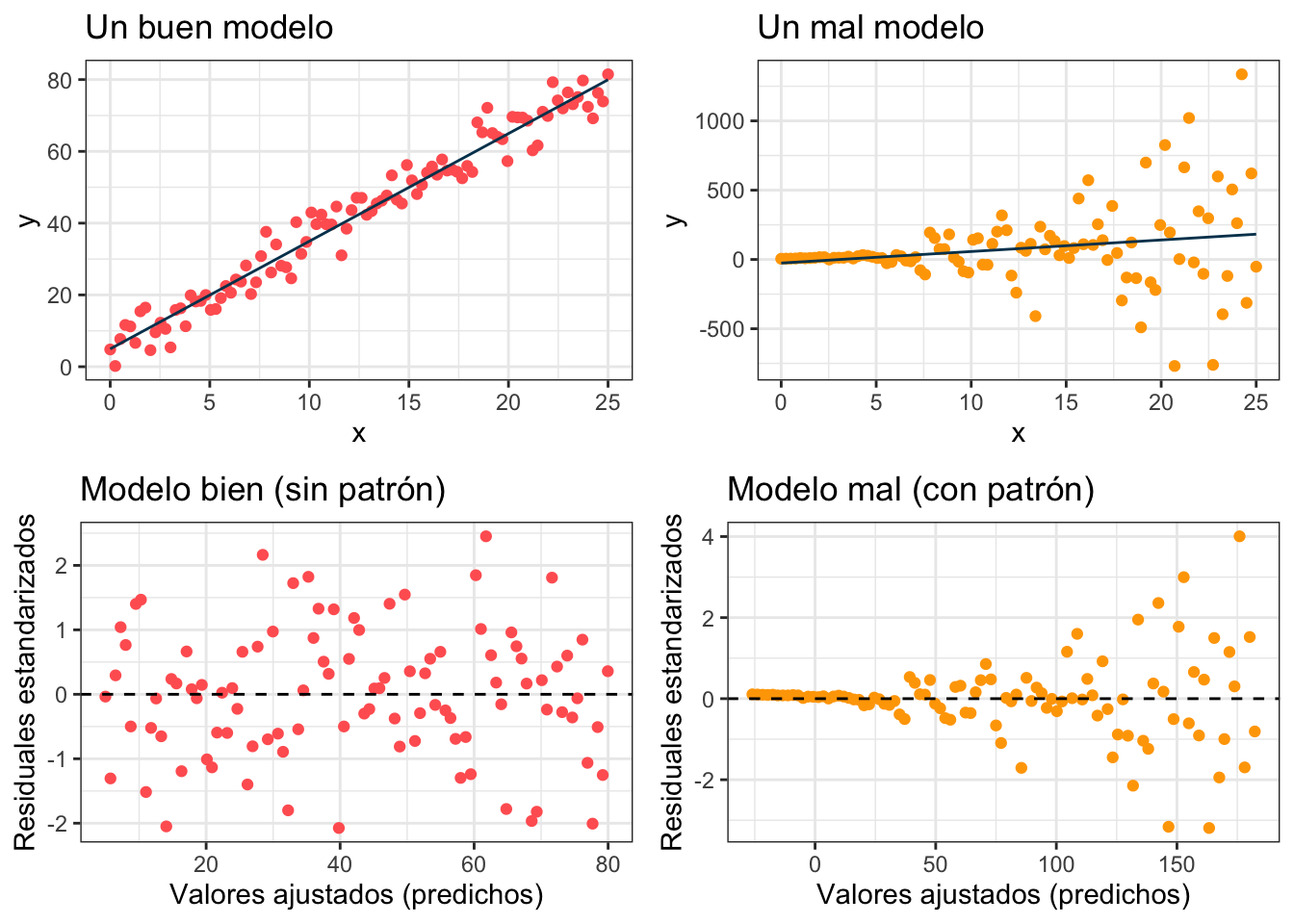
Podemos ver cómo se ven estos puntos en el modelo ideal vs en un modelo donde la \(\sigma^2\) depende de la \(x\):
Normal cuantil cuantil
La segunda gráfica corresponde a una gráfica cuantil cuantil. Esta la utilizamos para verificar la hipótesis de normalidad. En una gráfica cuantil cuantil se grafican los cuantiles de los residuales contra los cuantiles teóricos de la normal. Por ejemplo si la hacemos con sólo 4 puntos se vería algo así:
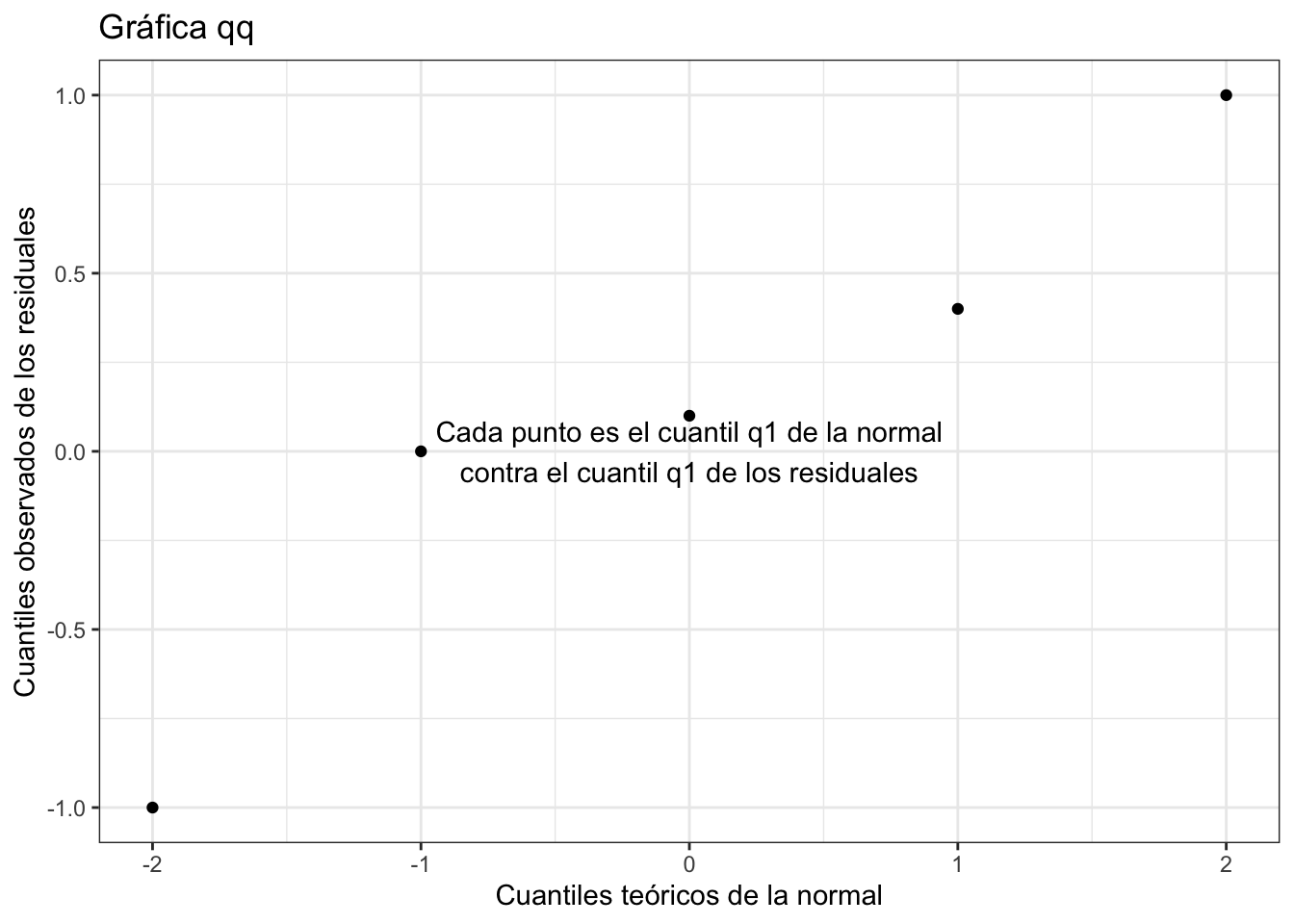
Podemos armar una gráfica cuantil cuantil con ggplot2:
ggplot(obs_y_modelo, aes(sample = residuales)) +
stat_qq(color = "#ff6361") +
stat_qq_line(color = "#58508d") +
theme_bw() +
labs(
x = "Cuantiles teóricos de la normal",
y = "Cuantiles observados de los residuales",
title = "Gráfica qq"
)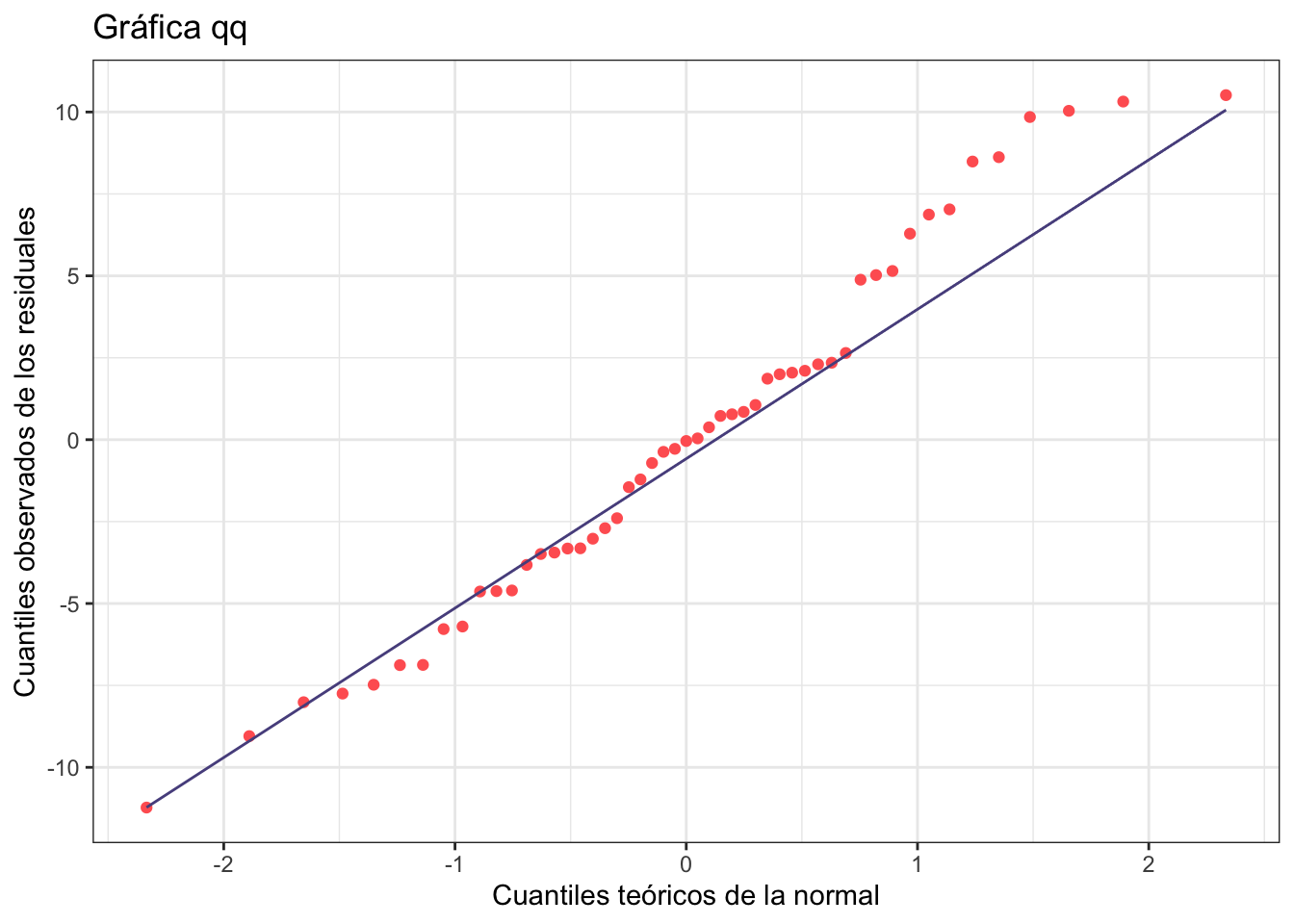
La idea de la gráfica cuantil cuantil es que los puntos sigan la línea lo más posible. Veamos cómo se ve con los datos bien (y los mal)
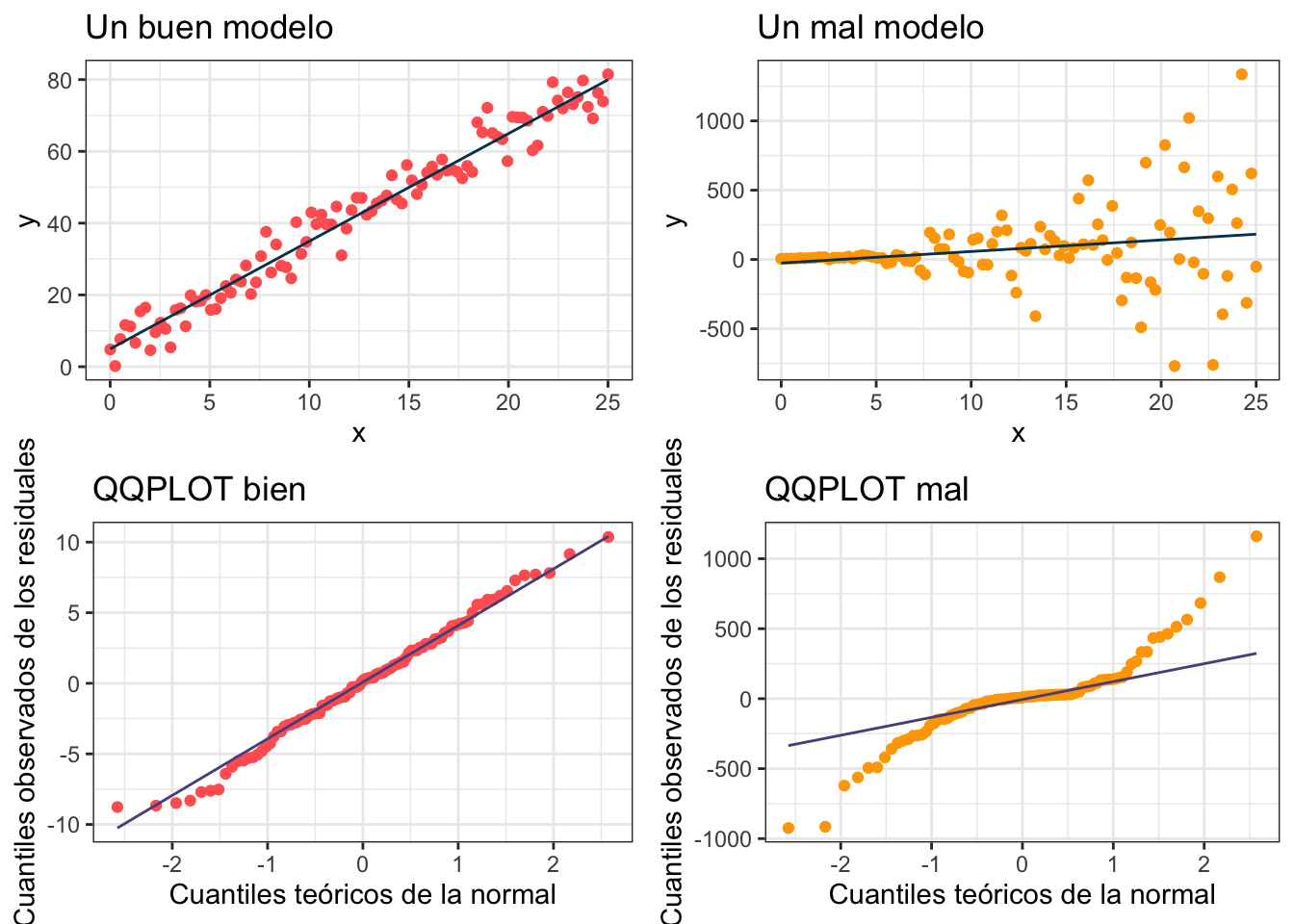
Residuales contra apalancamiento
El apalancamiento representa qué tanto cambia el modelo al quitar una sola observación. Para poner un ejemplo considera los siguientes datos donde hay un valor atípico y selecciono dos puntos de interés en dos colores:
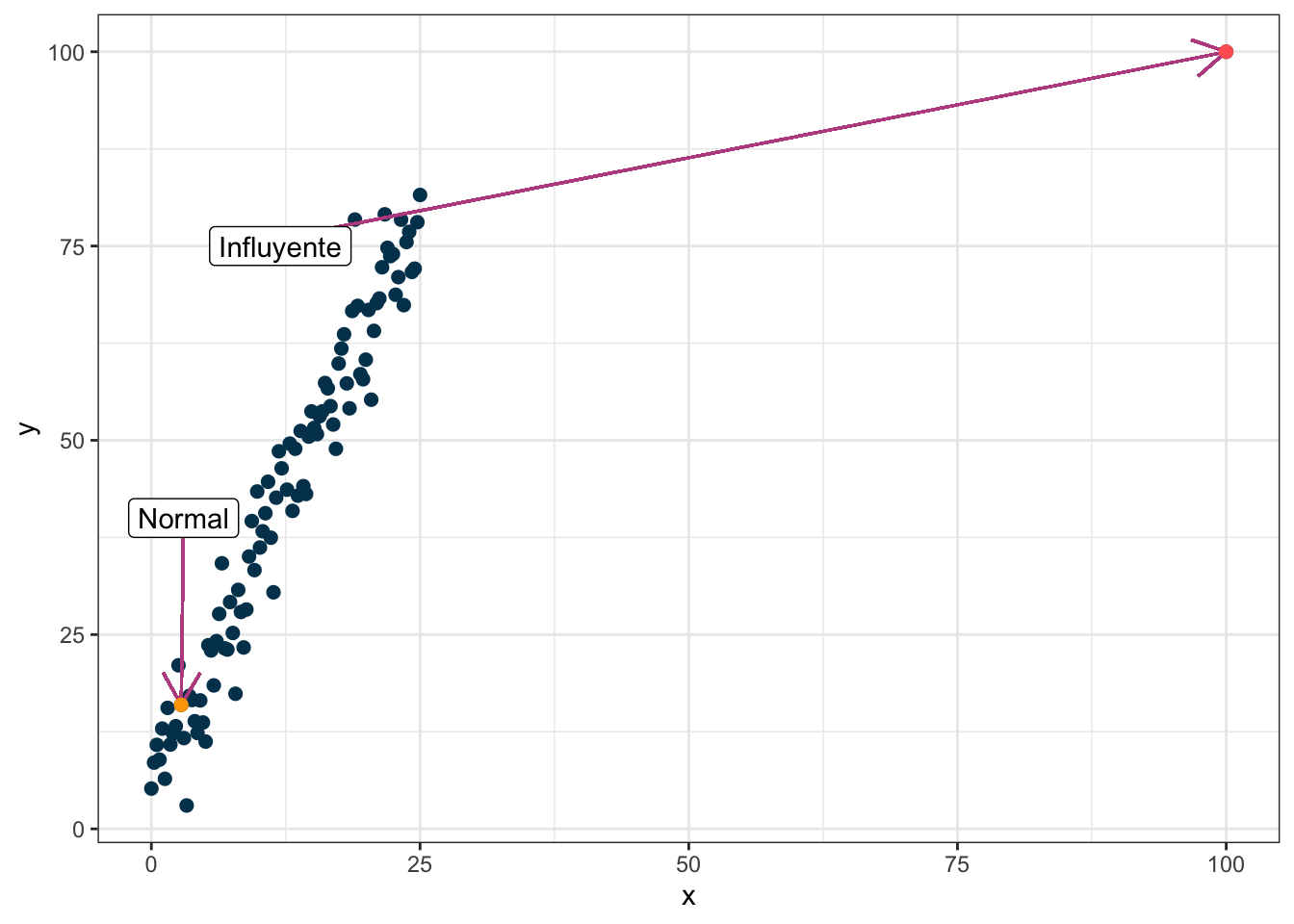
Veamos cómo cambia la regresión si dejo todos los puntos, si quito el normal y si quito el influyente:
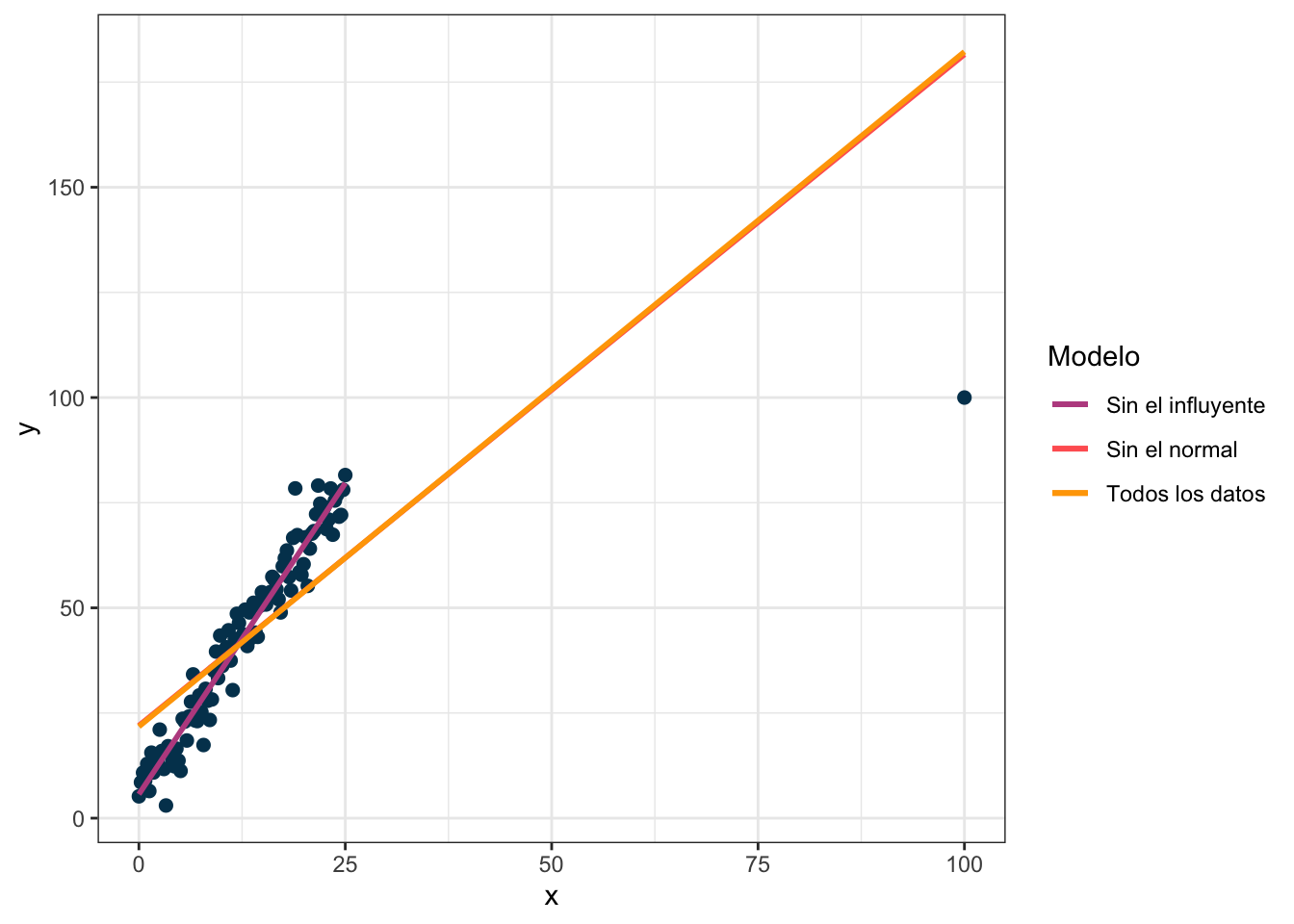
Nota que el modelo no cambia prácticamente nada cuando hago la regresión sin el dato que marqué como normal pero cambia mucho cuando quito el que marqué como influyente. La gráfica de residuales contra apalancamiento muestra también el valor extraño:
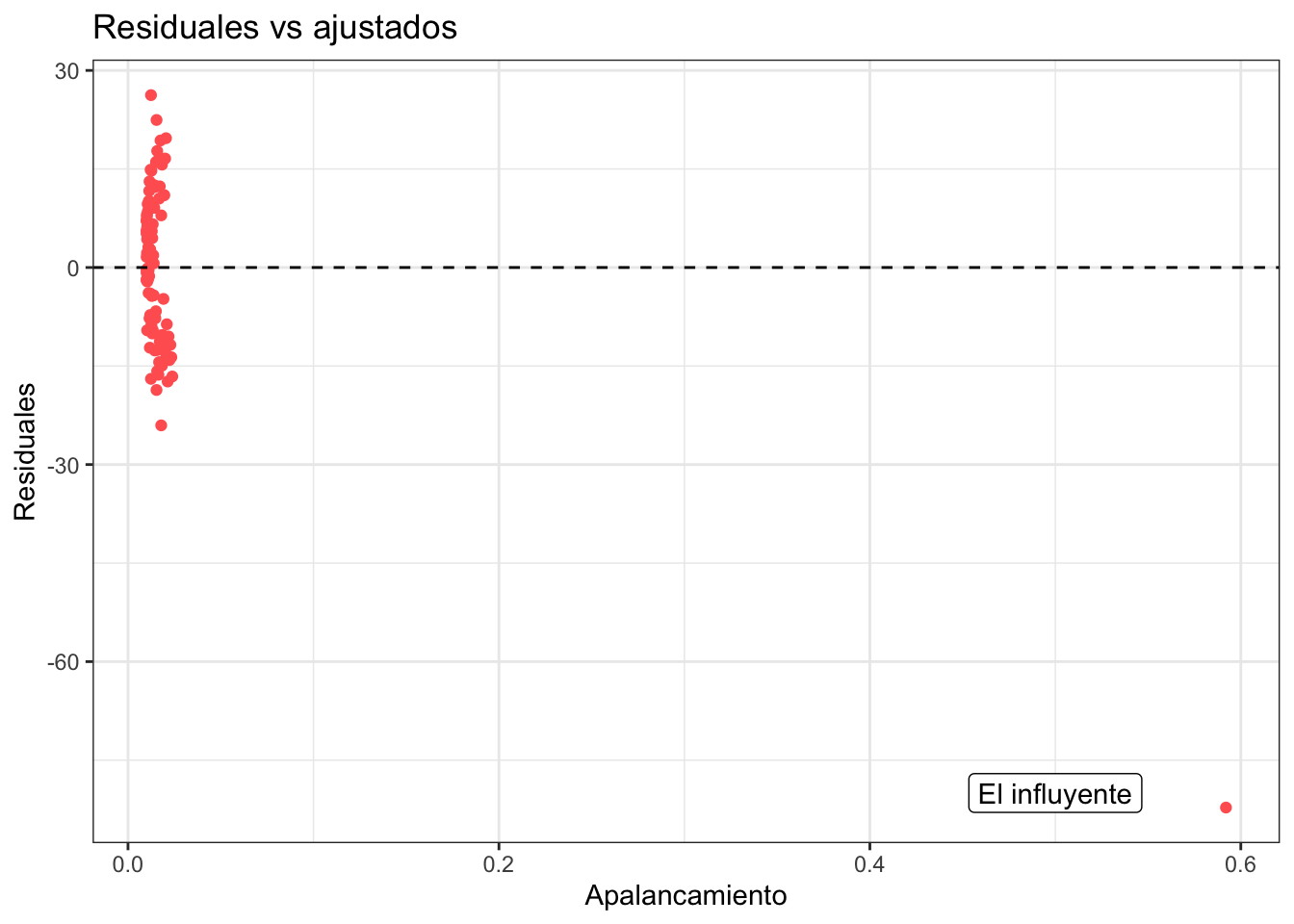
El apalancamiento mide la influencia de un dato y en R se puede calcular con hatvalues. Los datos con mayor apalancamiento siempre valen la pena checarlos para verificar que todo opera en orden.
apalancamiento <- modelo_ajustado %>%
extract_fit_engine() %>%
hatvalues()
obs_y_modelo <- obs_y_modelo %>%
cbind(apalancamiento)
#Graficamos residuales contra apalancamiento
ggplot(obs_y_modelo) +
geom_point(aes(x = apalancamiento, y = residuales), color = "#ff6361") +
labs(
x = "Apalancamiento",
y = "Residuales",
title = "Residuales vs ajustados"
) +
theme_bw() +
geom_hline(aes(yintercept = 0), linetype = "dashed")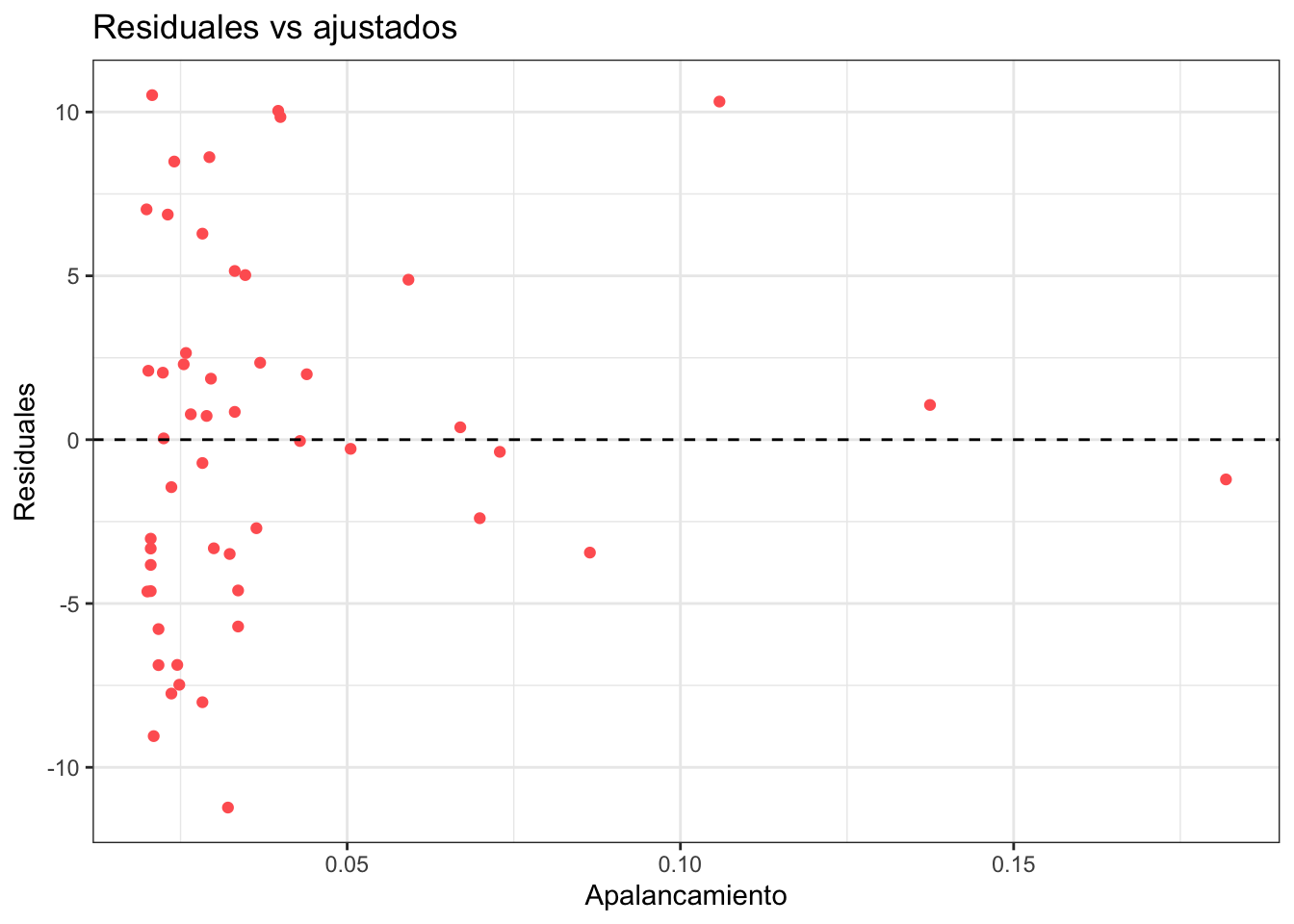
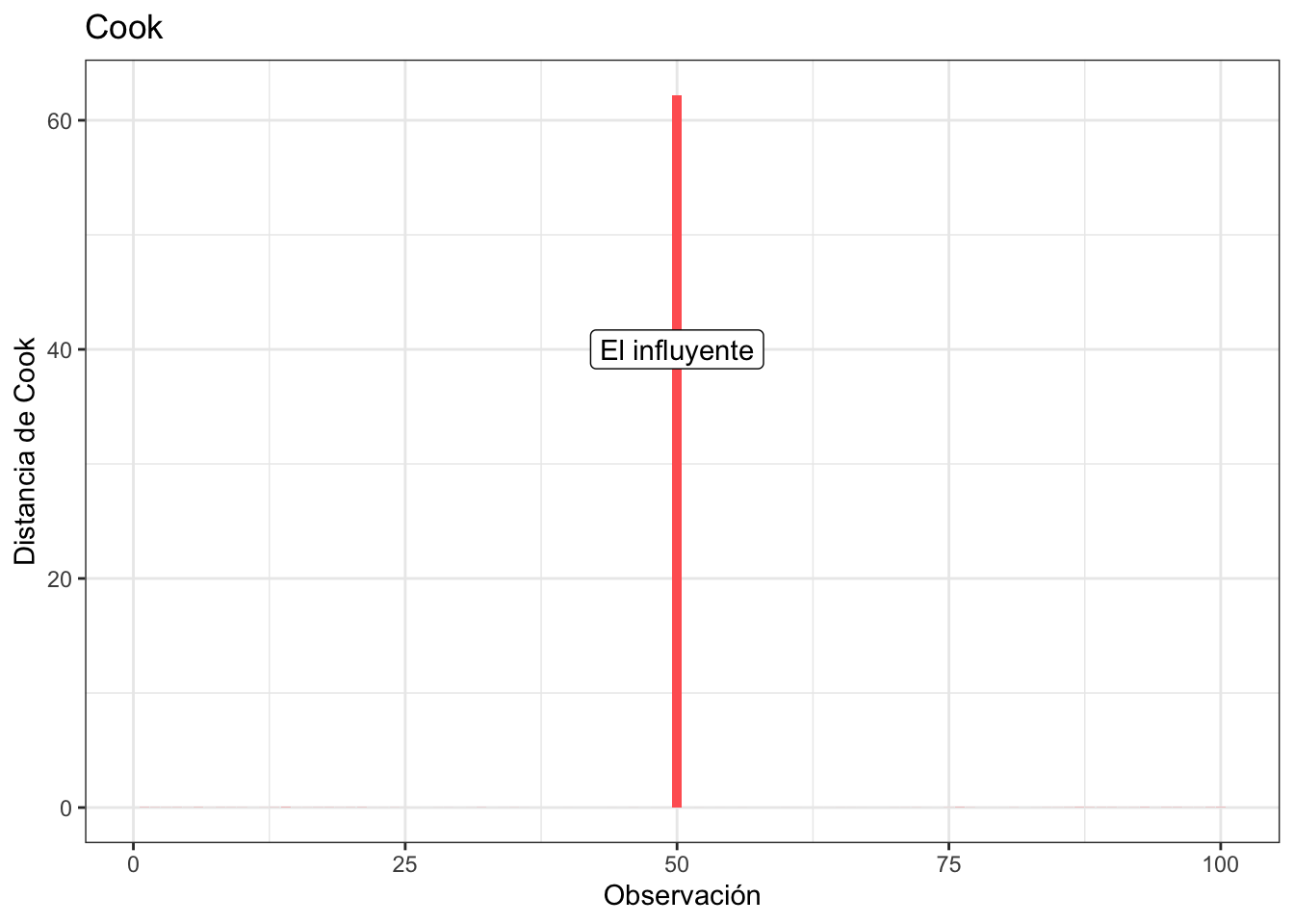
Distancia de Cook
La distancia de Cook es un concepto similar al apalancamiento que identifica observaciones influyentes. Aquellos valores con distancia de Cook alta vale la pena revisar. En R podemos usar cooks.distance para calcular la distancia de Cook.
distanciaCook <- modelo_ajustado %>%
extract_fit_engine() %>%
cooks.distance()
obs_y_modelo <- obs_y_modelo %>%
cbind(distanciaCook)
#Graficamos residuales contra apalancamiento
ggplot(obs_y_modelo) +
geom_col(aes(x = 1:nrow(obs_y_modelo), y = distanciaCook), fill = "#ff6361") +
labs(
x = "Observación (número de entrada en la base)",
y = "Distancia de Cook",
title = "Distancia de Cook"
) +
theme_bw() 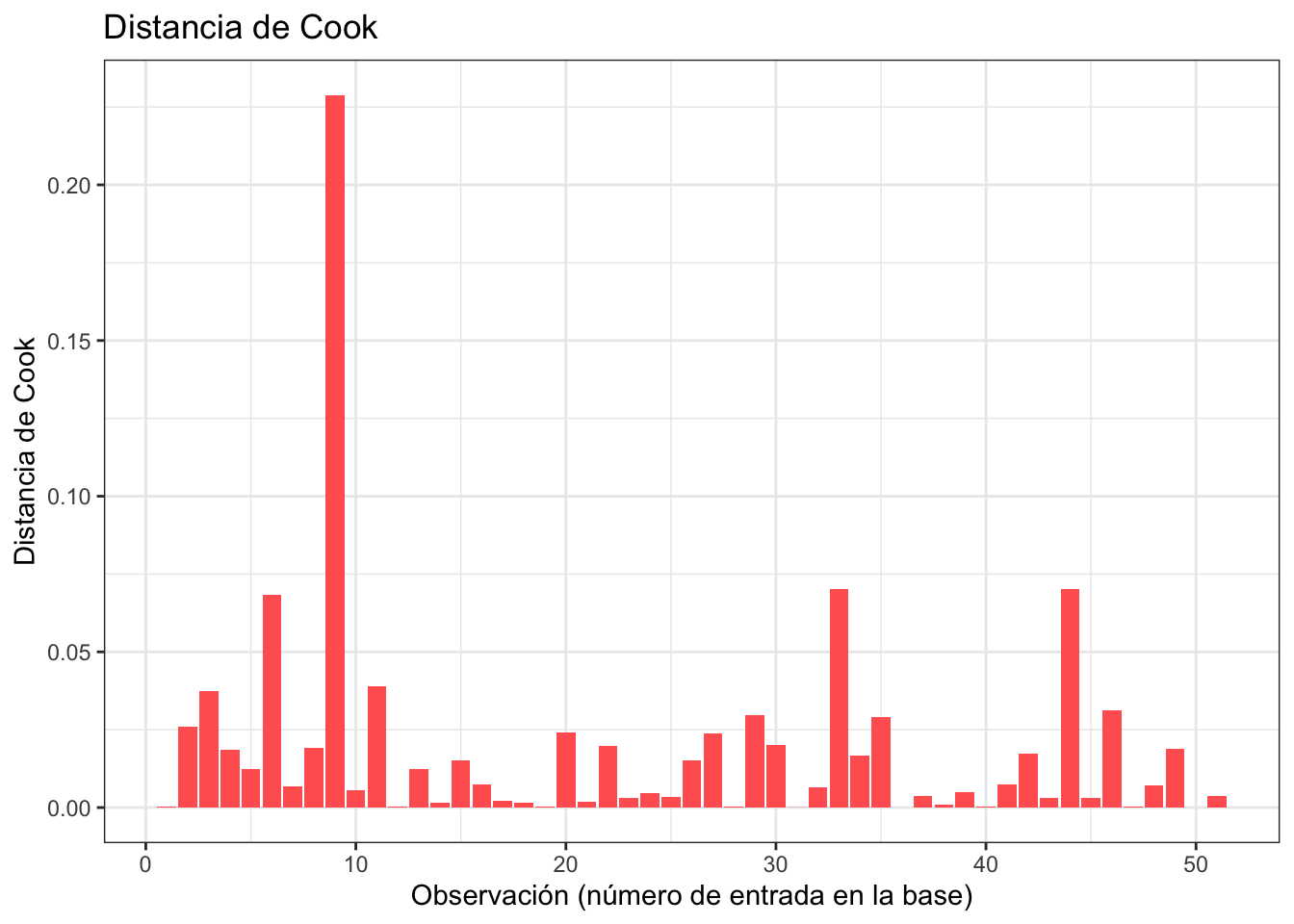
podemos ver que en el ejemplo anterior (el de la observación influyente) la distancia de Cook es exagerada, tan exagerada que ni se alcanzan a ver los otros:
Ejercicio
- Corre el siguiente código para generar una base de datos de nombre
datLongque contiene \(4\) grupos. Para cada grupo genere una regresión lineal de la forma:
\[ y = \beta_0 + \beta_1 x \]
Identifica cuáles regresiones sí ajustan bien y cuáles no mediante los gráficos de diagnóstico. Finalmente grafica tus datos \(x\) contra \(y\) y la regresión para ver que lo hayas hecho bien. ¿Hay alguna forma de corregir alguna de las que no ajusta bien?
dat <- datasets::anscombe
datLong <- data.frame(
grupo = rep(1:4, each = 11),
x = unlist(dat[,c(1:4)]),
y = unlist(dat[,c(5:8)])
)
rownames(datLong) <- NULLLee la base de datos de \(n = 345\) niños entre \(6\) y \(10\) años de Kahn, Michael (2005). Las variables de interés son \(y = \text{FEV}\) el volumen de expiración forzada y \(x = \text{edad}\) en años. Realiza una regresión lineal. Justifica que no se cumple la homocedasticidad mediante una gráfica de escala locación.
Plantee una regresión lineal usando los datos de esta liga para determinar si el sexo influye en el salario. Ojo en la regresión es necesario incluir otras covariables.
¿Y si lo hacemos bayesiano?
Para hacer la misma regresión lineal pero con estadística bayesiana podemos nada más cambiar el engine:
#Ajusta un modelo lineal
#Brth15to17 = intercepto + pendiente*PovPct
modelo_bayesiano <- linear_reg() %>%
set_engine("stan") %>%
fit(Brth15to17 ~ PovPct, data = emb_pob) #Notación y ~ xY podemos ver el ajuste:
modelo_bayesiano %>%
extract_fit_engine() %>%
summary()
Model Info:
function: stan_glm
family: gaussian [identity]
formula: Brth15to17 ~ PovPct
algorithm: sampling
sample: 4000 (posterior sample size)
priors: see help('prior_summary')
observations: 51
predictors: 2
Estimates:
mean sd 10% 50% 90%
(Intercept) 4.3 2.6 1.0 4.3 7.6
PovPct 1.4 0.2 1.1 1.4 1.6
sigma 5.7 0.6 4.9 5.6 6.4
Fit Diagnostics:
mean sd 10% 50% 90%
mean_PPD 22.3 1.1 20.8 22.2 23.7
The mean_ppd is the sample average posterior predictive distribution of the outcome variable (for details see help('summary.stanreg')).
MCMC diagnostics
mcse Rhat n_eff
(Intercept) 0.0 1.0 3382
PovPct 0.0 1.0 3269
sigma 0.0 1.0 3236
mean_PPD 0.0 1.0 3406
log-posterior 0.0 1.0 1430
For each parameter, mcse is Monte Carlo standard error, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence Rhat=1).o realizar predicciones:
predichos <- modelo_bayesiano %>%
extract_fit_engine() %>%
predict(new_data = emb_pob)
ic <- modelo_bayesiano %>%
extract_fit_engine() %>%
predictive_interval(newdata = emb_pob, prob = 0.95) #Para bayesiana
#Juntamos los predichos con los observados
obs_y_modelo <- emb_pob %>%
cbind(predichos) %>%
cbind(ic)
#Graficamos
ggplot(obs_y_modelo) +
geom_ribbon(aes(x = PovPct, ymin = `2.5%`, ymax = `97.5%`),
fill = "#003f5c", size = 1, alpha = 0.5) +
geom_point(aes(x = PovPct, y = Brth15to17), color = "#ffa600", size = 3) +
geom_line(aes(x = PovPct, y = predichos),
color = "#003f5c", size = 1) +
labs(
x = "Porcentaje en pobreza",
y = "Tasa bruta de natalidad (por cada 1,000 mujeres adolescentes)",
title = "Relación entre tasa bruta de natalidad en adolescentes\nde 15 a 19 años y porcentaje en pobreza"
) +
theme_bw()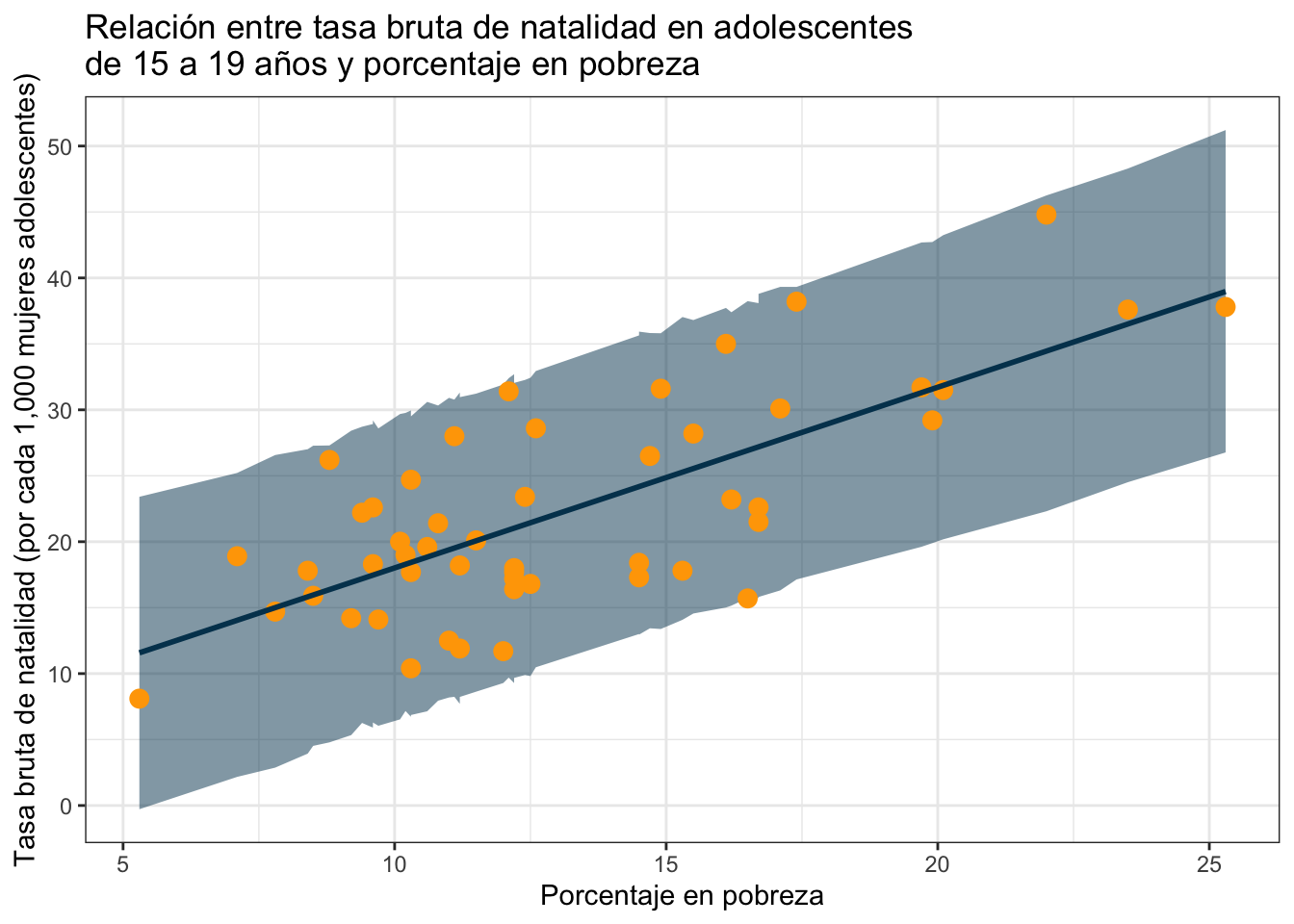
Para validación del modelo puedes checar esta página que explica loo (ver paper:
modelo_bayesiano %>%
extract_fit_engine() %>%
loo()
Computed from 4000 by 51 log-likelihood matrix
Estimate SE
elpd_loo -161.6 4.2
p_loo 2.4 0.5
looic 323.2 8.4
------
Monte Carlo SE of elpd_loo is 0.0.
All Pareto k estimates are good (k < 0.5).
See help('pareto-k-diagnostic') for details.asi como su visualización (si el modelo no fuera bueno)
modelo_bayesiano %>%
extract_fit_engine() %>%
loo() %>%
plot(label_points = TRUE)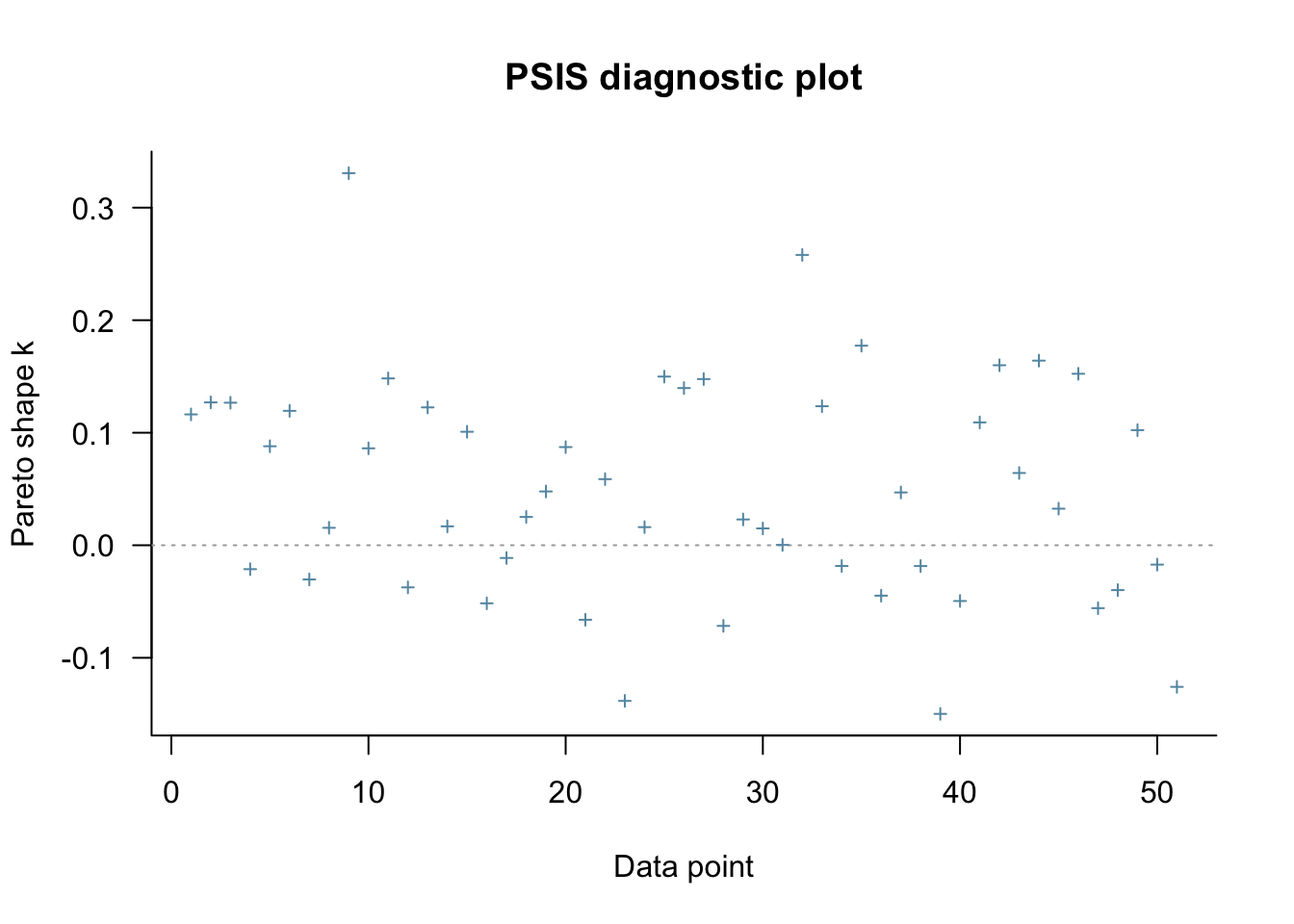
Ejercicio
- Utilice las opciones de
enginepara cambiar elprior_interceptdel intercepto a unatde Student y elpriorde los coeficientes a unaLaplace. ¿Cambia mucho el resultado?
Continuación
Sistema
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.2.1 (2022-06-23)
os macOS Big Sur ... 10.16
system x86_64, darwin17.0
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/Mexico_City
date 2022-10-05
pandoc 2.19.2 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.0)
backports 1.4.1 2021-12-13 [1] CRAN (R 4.2.0)
base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.2.0)
bayesplot 1.9.0 2022-03-10 [1] CRAN (R 4.2.0)
bit 4.0.4 2020-08-04 [1] CRAN (R 4.2.0)
bit64 4.0.5 2020-08-30 [1] CRAN (R 4.2.0)
boot 1.3-28 2021-05-03 [1] CRAN (R 4.2.1)
broom * 1.0.1 2022-08-29 [1] CRAN (R 4.2.0)
cachem 1.0.6 2021-08-19 [1] CRAN (R 4.2.0)
callr 3.7.2 2022-08-22 [1] CRAN (R 4.2.0)
cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.2.0)
class 7.3-20 2022-01-16 [1] CRAN (R 4.2.1)
cli 3.4.1 2022-09-23 [1] CRAN (R 4.2.0)
codetools 0.2-18 2020-11-04 [1] CRAN (R 4.2.1)
colorspace 2.0-3 2022-02-21 [1] CRAN (R 4.2.0)
colourpicker 1.1.1 2021-10-04 [1] CRAN (R 4.2.0)
conflicted 1.1.0 2021-11-26 [1] CRAN (R 4.2.0)
cowplot * 1.1.1 2020-12-30 [1] CRAN (R 4.2.0)
crayon 1.5.2 2022-09-29 [1] CRAN (R 4.2.0)
crosstalk 1.2.0 2021-11-04 [1] CRAN (R 4.2.0)
curl 4.3.2 2021-06-23 [1] CRAN (R 4.2.0)
DBI 1.1.3 2022-06-18 [1] CRAN (R 4.2.0)
dbplyr 2.2.1 2022-06-27 [1] CRAN (R 4.2.0)
dials * 1.0.0 2022-06-14 [1] CRAN (R 4.2.0)
DiceDesign 1.9 2021-02-13 [1] CRAN (R 4.2.0)
digest 0.6.29 2021-12-01 [1] CRAN (R 4.2.0)
dplyr * 1.0.10 2022-09-01 [1] CRAN (R 4.2.0)
DT 0.25 2022-09-12 [1] CRAN (R 4.2.0)
dygraphs 1.1.1.6 2018-07-11 [1] CRAN (R 4.2.0)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.2.0)
evaluate 0.16 2022-08-09 [1] CRAN (R 4.2.0)
fansi 1.0.3 2022-03-24 [1] CRAN (R 4.2.0)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.2.0)
fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.0)
forcats * 0.5.2 2022-08-19 [1] CRAN (R 4.2.0)
foreach 1.5.2 2022-02-02 [1] CRAN (R 4.2.0)
fs 1.5.2 2021-12-08 [1] CRAN (R 4.2.0)
furrr 0.3.1 2022-08-15 [1] CRAN (R 4.2.0)
future 1.28.0 2022-09-02 [1] CRAN (R 4.2.0)
future.apply 1.9.1 2022-09-07 [1] CRAN (R 4.2.0)
gargle 1.2.1 2022-09-08 [1] CRAN (R 4.2.0)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.2.0)
ggfortify * 0.4.14 2022-01-03 [1] CRAN (R 4.2.0)
ggplot2 * 3.3.6 2022-05-03 [1] CRAN (R 4.2.0)
ggridges * 0.5.4 2022-09-26 [1] CRAN (R 4.2.0)
globals 0.16.1 2022-08-28 [1] CRAN (R 4.2.0)
glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
googledrive 2.0.0 2021-07-08 [1] CRAN (R 4.2.0)
googlesheets4 1.0.1 2022-08-13 [1] CRAN (R 4.2.0)
gower 1.0.0 2022-02-03 [1] CRAN (R 4.2.0)
GPfit 1.0-8 2019-02-08 [1] CRAN (R 4.2.0)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.2.0)
gtable 0.3.1 2022-09-01 [1] CRAN (R 4.2.0)
gtools 3.9.3 2022-07-11 [1] CRAN (R 4.2.0)
hardhat 1.2.0 2022-06-30 [1] CRAN (R 4.2.0)
haven 2.5.1 2022-08-22 [1] CRAN (R 4.2.0)
hms 1.1.2 2022-08-19 [1] CRAN (R 4.2.0)
htmltools 0.5.3 2022-07-18 [1] CRAN (R 4.2.0)
htmlwidgets 1.5.4 2021-09-08 [1] CRAN (R 4.2.0)
httpuv 1.6.6 2022-09-08 [1] CRAN (R 4.2.0)
httr 1.4.4 2022-08-17 [1] CRAN (R 4.2.0)
igraph 1.3.5 2022-09-22 [1] CRAN (R 4.2.0)
infer * 1.0.3 2022-08-22 [1] CRAN (R 4.2.0)
inline 0.3.19 2021-05-31 [1] CRAN (R 4.2.0)
ipred 0.9-13 2022-06-02 [1] CRAN (R 4.2.0)
iterators 1.0.14 2022-02-05 [1] CRAN (R 4.2.0)
jsonlite 1.8.2 2022-10-02 [1] CRAN (R 4.2.0)
knitr 1.40 2022-08-24 [1] CRAN (R 4.2.0)
labeling 0.4.2 2020-10-20 [1] CRAN (R 4.2.0)
later 1.3.0 2021-08-18 [1] CRAN (R 4.2.0)
lattice 0.20-45 2021-09-22 [1] CRAN (R 4.2.1)
lava 1.6.10 2021-09-02 [1] CRAN (R 4.2.0)
lhs 1.1.5 2022-03-22 [1] CRAN (R 4.2.0)
lifecycle 1.0.2 2022-09-09 [1] CRAN (R 4.2.0)
listenv 0.8.0 2019-12-05 [1] CRAN (R 4.2.0)
lme4 1.1-30 2022-07-08 [1] CRAN (R 4.2.0)
loo 2.5.1 2022-03-24 [1] CRAN (R 4.2.0)
lubridate 1.8.0 2021-10-07 [1] CRAN (R 4.2.0)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0)
markdown 1.1 2019-08-07 [1] CRAN (R 4.2.0)
MASS 7.3-58.1 2022-08-03 [1] CRAN (R 4.2.0)
Matrix 1.5-1 2022-09-13 [1] CRAN (R 4.2.0)
matrixStats 0.62.0 2022-04-19 [1] CRAN (R 4.2.0)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.2.0)
mgcv 1.8-40 2022-03-29 [1] CRAN (R 4.2.1)
mime 0.12 2021-09-28 [1] CRAN (R 4.2.0)
miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.2.0)
minqa 1.2.4 2014-10-09 [1] CRAN (R 4.2.0)
modeldata * 1.0.1 2022-09-06 [1] CRAN (R 4.2.0)
modelr 0.1.9 2022-08-19 [1] CRAN (R 4.2.0)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.2.0)
nlme 3.1-159 2022-08-09 [1] CRAN (R 4.2.0)
nloptr 2.0.3 2022-05-26 [1] CRAN (R 4.2.0)
nnet 7.3-18 2022-09-28 [1] CRAN (R 4.2.0)
parallelly 1.32.1 2022-07-21 [1] CRAN (R 4.2.0)
parsnip * 1.0.2 2022-10-01 [1] CRAN (R 4.2.0)
pillar 1.8.1 2022-08-19 [1] CRAN (R 4.2.0)
pkgbuild 1.3.1 2021-12-20 [1] CRAN (R 4.2.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.0)
plyr 1.8.7 2022-03-24 [1] CRAN (R 4.2.0)
poissonreg * 1.0.1 2022-08-22 [1] CRAN (R 4.2.0)
prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.2.0)
processx 3.7.0 2022-07-07 [1] CRAN (R 4.2.0)
prodlim 2019.11.13 2019-11-17 [1] CRAN (R 4.2.0)
promises 1.2.0.1 2021-02-11 [1] CRAN (R 4.2.0)
ps 1.7.1 2022-06-18 [1] CRAN (R 4.2.0)
purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.2.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
Rcpp * 1.0.9 2022-07-08 [1] CRAN (R 4.2.0)
RcppParallel 5.1.5 2022-01-05 [1] CRAN (R 4.2.0)
readr * 2.1.3 2022-10-01 [1] CRAN (R 4.2.0)
readxl 1.4.1 2022-08-17 [1] CRAN (R 4.2.0)
recipes * 1.0.1 2022-07-07 [1] CRAN (R 4.2.0)
reprex 2.0.2 2022-08-17 [1] CRAN (R 4.2.0)
reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.2.0)
rlang 1.0.6 2022-09-24 [1] CRAN (R 4.2.0)
rmarkdown 2.16 2022-08-24 [1] CRAN (R 4.2.0)
rpart 4.1.16 2022-01-24 [1] CRAN (R 4.2.1)
rsample * 1.1.0 2022-08-08 [1] CRAN (R 4.2.0)
rstan 2.21.7 2022-09-08 [1] CRAN (R 4.2.0)
rstanarm * 2.21.3 2022-04-09 [1] CRAN (R 4.2.0)
rstantools 2.2.0 2022-04-08 [1] CRAN (R 4.2.0)
rstudioapi 0.14 2022-08-22 [1] CRAN (R 4.2.0)
rvest 1.0.3 2022-08-19 [1] CRAN (R 4.2.0)
scales * 1.2.1 2022-08-20 [1] CRAN (R 4.2.0)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
shiny 1.7.2 2022-07-19 [1] CRAN (R 4.2.0)
shinyjs 2.1.0 2021-12-23 [1] CRAN (R 4.2.0)
shinystan 2.6.0 2022-03-03 [1] CRAN (R 4.2.0)
shinythemes 1.2.0 2021-01-25 [1] CRAN (R 4.2.0)
StanHeaders 2.21.0-7 2020-12-17 [1] CRAN (R 4.2.0)
stringi 1.7.8 2022-07-11 [1] CRAN (R 4.2.0)
stringr * 1.4.1 2022-08-20 [1] CRAN (R 4.2.0)
survival 3.4-0 2022-08-09 [1] CRAN (R 4.2.0)
threejs 0.3.3 2020-01-21 [1] CRAN (R 4.2.0)
tibble * 3.1.8 2022-07-22 [1] CRAN (R 4.2.0)
tidymodels * 1.0.0 2022-07-13 [1] CRAN (R 4.2.0)
tidyr * 1.2.1 2022-09-08 [1] CRAN (R 4.2.0)
tidyselect 1.1.2 2022-02-21 [1] CRAN (R 4.2.0)
tidyverse * 1.3.2 2022-07-18 [1] CRAN (R 4.2.0)
timeDate 4021.106 2022-09-30 [1] CRAN (R 4.2.0)
tune * 1.0.0 2022-07-07 [1] CRAN (R 4.2.0)
tzdb 0.3.0 2022-03-28 [1] CRAN (R 4.2.0)
utf8 1.2.2 2021-07-24 [1] CRAN (R 4.2.0)
vctrs 0.4.2 2022-09-29 [1] CRAN (R 4.2.0)
vroom 1.6.0 2022-09-30 [1] CRAN (R 4.2.0)
withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.0)
workflows * 1.1.0 2022-09-26 [1] CRAN (R 4.2.0)
workflowsets * 1.0.0 2022-07-12 [1] CRAN (R 4.2.0)
xfun 0.33 2022-09-12 [1] CRAN (R 4.2.0)
xml2 1.3.3 2021-11-30 [1] CRAN (R 4.2.0)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.2.0)
xts 0.12.1 2020-09-09 [1] CRAN (R 4.2.0)
yaml 2.3.5 2022-02-21 [1] CRAN (R 4.2.0)
yardstick * 1.1.0 2022-09-07 [1] CRAN (R 4.2.0)
zoo 1.8-11 2022-09-17 [1] CRAN (R 4.2.0)
[1] /Library/Frameworks/R.framework/Versions/4.2/Resources/library
──────────────────────────────────────────────────────────────────────────────